6.2 ハッシュ衝突¶
前節で述べたように、**通常、ハッシュ関数の入力空間は出力空間よりもはるかに大きい**ため、理論上ハッシュ衝突は避けられません。例えば、入力空間がすべての整数で、出力空間が配列の容量サイズである場合、必然的に複数の整数が同じバケットインデックスに写像されます。
ハッシュ衝突は検索結果の誤りを招き、ハッシュテーブルの利用可能性に深刻な影響を与えます。この問題を解決するために、ハッシュ衝突が発生するたびにハッシュテーブルを拡張し、衝突が消えるまで続けることが考えられます。この方法は単純で効果的ですが、効率が低すぎます。なぜなら、ハッシュテーブルの拡張には大量のデータ移動とハッシュ値の計算が必要だからです。効率を高めるために、次の戦略を採用できます。
- ハッシュテーブルのデータ構造を改良し、ハッシュ衝突が発生してもハッシュテーブルが正常に動作できるようにする。
- 必要な場合、すなわちハッシュ衝突が比較的深刻なときにのみ、拡張操作を実行する。
ハッシュテーブルの構造改善方法には、主に「チェイン法」と「オープンアドレッシング」があります。
6.2.1 チェイン法¶
元のハッシュテーブルでは、各バケットには 1 つのキーと値のペアしか格納できません。チェイン法(separate chaining)では、単一要素を連結リストに置き換え、キーと値のペアを連結リストのノードとして扱い、衝突したすべてのキーと値のペアを同じ連結リストに格納します。下図はチェイン法によるハッシュテーブルの例を示しています。
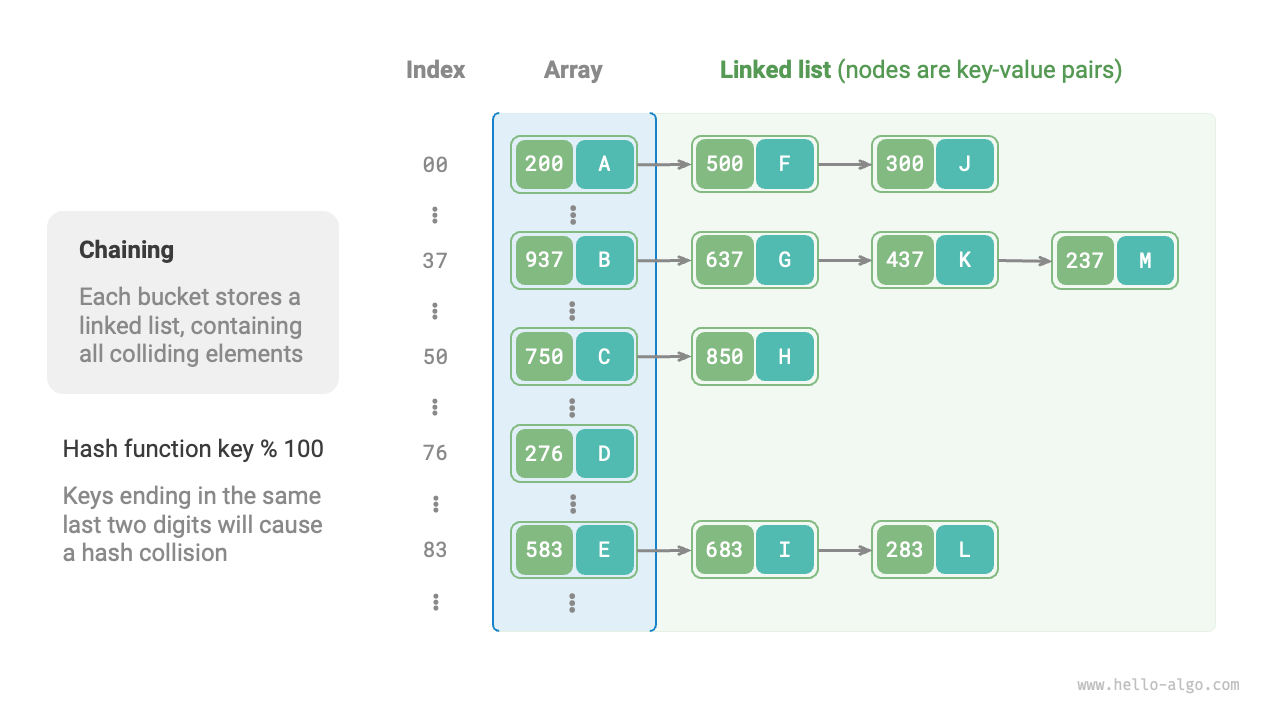
図 6-5 チェイン法ハッシュテーブル
チェイン法で実装されたハッシュテーブルでは、操作方法が次のように変わります。
- 要素の検索:入力
keyをハッシュ関数に通してバケットインデックスを得ると、連結リストの先頭ノードにアクセスできます。その後、連結リストを走査してkeyを比較し、目的のキーと値のペアを探します。 - 要素の追加:まずハッシュ関数で連結リストの先頭ノードにアクセスし、その後ノード(キーと値のペア)を連結リストに追加します。
- 要素の削除:ハッシュ関数の結果に基づいて連結リストの先頭にアクセスし、続いて連結リストを走査して対象ノードを探し、削除します。
チェイン法には次の制約があります。
- 使用メモリの増加:連結リストにはノードポインタが含まれるため、配列よりも多くのメモリを消費します。
- 検索効率の低下:対応する要素を見つけるために連結リストを線形走査する必要があるためです。
以下のコードはチェイン法ハッシュテーブルの簡単な実装を示しています。注意すべき点は 2 つあります。
- 連結リストの代わりにリスト(動的配列)を使って、コードを簡潔にしています。この設定では、ハッシュテーブル(配列)は複数のバケットを含み、各バケットは 1 つのリストです。
- 以下の実装にはハッシュテーブルの拡張メソッドが含まれています。負荷率が \(\frac{2}{3}\) を超えたとき、ハッシュテーブルを元の \(2\) 倍に拡張します。
class HashMapChaining:
"""チェイン法ハッシュテーブル"""
def __init__(self):
"""コンストラクタ"""
self.size = 0 # キーと値のペア数
self.capacity = 4 # ハッシュテーブル容量
self.load_thres = 2.0 / 3.0 # リサイズを発動する負荷率のしきい値
self.extend_ratio = 2 # 拡張倍率
self.buckets = [[] for _ in range(self.capacity)] # バケット配列
def hash_func(self, key: int) -> int:
"""ハッシュ関数"""
return key % self.capacity
def load_factor(self) -> float:
"""負荷率"""
return self.size / self.capacity
def get(self, key: int) -> str | None:
"""検索操作"""
index = self.hash_func(key)
bucket = self.buckets[index]
# バケットを走査し、key が見つかれば対応する val を返す
for pair in bucket:
if pair.key == key:
return pair.val
# key が見つからない場合は None を返す
return None
def put(self, key: int, val: str):
"""追加操作"""
# 負荷率がしきい値を超えたら、リサイズを実行
if self.load_factor() > self.load_thres:
self.extend()
index = self.hash_func(key)
bucket = self.buckets[index]
# バケットを走査し、指定した key が見つかれば対応する val を更新して返す
for pair in bucket:
if pair.key == key:
pair.val = val
return
# その key が存在しなければ、キーと値のペアを末尾に追加
pair = Pair(key, val)
bucket.append(pair)
self.size += 1
def remove(self, key: int):
"""削除操作"""
index = self.hash_func(key)
bucket = self.buckets[index]
# バケットを走査してキーと値のペアを削除
for pair in bucket:
if pair.key == key:
bucket.remove(pair)
self.size -= 1
break
def extend(self):
"""ハッシュテーブルを拡張"""
# 元のハッシュテーブルを一時保存
buckets = self.buckets
# リサイズ後の新しいハッシュテーブルを初期化
self.capacity *= self.extend_ratio
self.buckets = [[] for _ in range(self.capacity)]
self.size = 0
# キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for bucket in buckets:
for pair in bucket:
self.put(pair.key, pair.val)
def print(self):
"""ハッシュテーブルを出力"""
for bucket in self.buckets:
res = []
for pair in bucket:
res.append(str(pair.key) + " -> " + pair.val)
print(res)
/* チェイン法ハッシュテーブル */
class HashMapChaining {
private:
int size; // キーと値のペア数
int capacity; // ハッシュテーブル容量
double loadThres; // リサイズを発動する負荷率のしきい値
int extendRatio; // 拡張倍率
vector<vector<Pair *>> buckets; // バケット配列
public:
/* コンストラクタ */
HashMapChaining() : size(0), capacity(4), loadThres(2.0 / 3.0), extendRatio(2) {
buckets.resize(capacity);
}
/* デストラクタメソッド */
~HashMapChaining() {
for (auto &bucket : buckets) {
for (Pair *pair : bucket) {
// メモリを解放する
delete pair;
}
}
}
/* ハッシュ関数 */
int hashFunc(int key) {
return key % capacity;
}
/* 負荷率 */
double loadFactor() {
return (double)size / (double)capacity;
}
/* 検索操作 */
string get(int key) {
int index = hashFunc(key);
// バケットを走査し、key が見つかれば対応する val を返す
for (Pair *pair : buckets[index]) {
if (pair->key == key) {
return pair->val;
}
}
// key が見つからない場合は空文字列を返す
return "";
}
/* 追加操作 */
void put(int key, string val) {
// 負荷率がしきい値を超えたら、リサイズを実行
if (loadFactor() > loadThres) {
extend();
}
int index = hashFunc(key);
// バケットを走査し、指定した key が見つかれば対応する val を更新して返す
for (Pair *pair : buckets[index]) {
if (pair->key == key) {
pair->val = val;
return;
}
}
// その key が存在しなければ、キーと値のペアを末尾に追加
buckets[index].push_back(new Pair(key, val));
size++;
}
/* 削除操作 */
void remove(int key) {
int index = hashFunc(key);
auto &bucket = buckets[index];
// バケットを走査してキーと値のペアを削除
for (int i = 0; i < bucket.size(); i++) {
if (bucket[i]->key == key) {
Pair *tmp = bucket[i];
bucket.erase(bucket.begin() + i); // そこからキーと値の組を削除する
delete tmp; // メモリを解放する
size--;
return;
}
}
}
/* ハッシュテーブルを拡張 */
void extend() {
// 元のハッシュテーブルを一時保存
vector<vector<Pair *>> bucketsTmp = buckets;
// リサイズ後の新しいハッシュテーブルを初期化
capacity *= extendRatio;
buckets.clear();
buckets.resize(capacity);
size = 0;
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for (auto &bucket : bucketsTmp) {
for (Pair *pair : bucket) {
put(pair->key, pair->val);
// メモリを解放する
delete pair;
}
}
}
/* ハッシュテーブルを出力 */
void print() {
for (auto &bucket : buckets) {
cout << "[";
for (Pair *pair : bucket) {
cout << pair->key << " -> " << pair->val << ", ";
}
cout << "]\n";
}
}
};
/* チェイン法ハッシュテーブル */
class HashMapChaining {
int size; // キーと値のペア数
int capacity; // ハッシュテーブル容量
double loadThres; // リサイズを発動する負荷率のしきい値
int extendRatio; // 拡張倍率
List<List<Pair>> buckets; // バケット配列
/* コンストラクタ */
public HashMapChaining() {
size = 0;
capacity = 4;
loadThres = 2.0 / 3.0;
extendRatio = 2;
buckets = new ArrayList<>(capacity);
for (int i = 0; i < capacity; i++) {
buckets.add(new ArrayList<>());
}
}
/* ハッシュ関数 */
int hashFunc(int key) {
return key % capacity;
}
/* 負荷率 */
double loadFactor() {
return (double) size / capacity;
}
/* 検索操作 */
String get(int key) {
int index = hashFunc(key);
List<Pair> bucket = buckets.get(index);
// バケットを走査し、key が見つかれば対応する val を返す
for (Pair pair : bucket) {
if (pair.key == key) {
return pair.val;
}
}
// key が見つからない場合は null を返す
return null;
}
/* 追加操作 */
void put(int key, String val) {
// 負荷率がしきい値を超えたら、リサイズを実行
if (loadFactor() > loadThres) {
extend();
}
int index = hashFunc(key);
List<Pair> bucket = buckets.get(index);
// バケットを走査し、指定した key が見つかれば対応する val を更新して返す
for (Pair pair : bucket) {
if (pair.key == key) {
pair.val = val;
return;
}
}
// その key が存在しなければ、キーと値のペアを末尾に追加
Pair pair = new Pair(key, val);
bucket.add(pair);
size++;
}
/* 削除操作 */
void remove(int key) {
int index = hashFunc(key);
List<Pair> bucket = buckets.get(index);
// バケットを走査してキーと値のペアを削除
for (Pair pair : bucket) {
if (pair.key == key) {
bucket.remove(pair);
size--;
break;
}
}
}
/* ハッシュテーブルを拡張 */
void extend() {
// 元のハッシュテーブルを一時保存
List<List<Pair>> bucketsTmp = buckets;
// リサイズ後の新しいハッシュテーブルを初期化
capacity *= extendRatio;
buckets = new ArrayList<>(capacity);
for (int i = 0; i < capacity; i++) {
buckets.add(new ArrayList<>());
}
size = 0;
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for (List<Pair> bucket : bucketsTmp) {
for (Pair pair : bucket) {
put(pair.key, pair.val);
}
}
}
/* ハッシュテーブルを出力 */
void print() {
for (List<Pair> bucket : buckets) {
List<String> res = new ArrayList<>();
for (Pair pair : bucket) {
res.add(pair.key + " -> " + pair.val);
}
System.out.println(res);
}
}
}
/* チェイン法ハッシュテーブル */
class HashMapChaining {
int size; // キーと値のペア数
int capacity; // ハッシュテーブル容量
double loadThres; // リサイズを発動する負荷率のしきい値
int extendRatio; // 拡張倍率
List<List<Pair>> buckets; // バケット配列
/* コンストラクタ */
public HashMapChaining() {
size = 0;
capacity = 4;
loadThres = 2.0 / 3.0;
extendRatio = 2;
buckets = new List<List<Pair>>(capacity);
for (int i = 0; i < capacity; i++) {
buckets.Add([]);
}
}
/* ハッシュ関数 */
int HashFunc(int key) {
return key % capacity;
}
/* 負荷率 */
double LoadFactor() {
return (double)size / capacity;
}
/* 検索操作 */
public string? Get(int key) {
int index = HashFunc(key);
// バケットを走査し、key が見つかれば対応する val を返す
foreach (Pair pair in buckets[index]) {
if (pair.key == key) {
return pair.val;
}
}
// key が見つからない場合は null を返す
return null;
}
/* 追加操作 */
public void Put(int key, string val) {
// 負荷率がしきい値を超えたら、リサイズを実行
if (LoadFactor() > loadThres) {
Extend();
}
int index = HashFunc(key);
// バケットを走査し、指定した key が見つかれば対応する val を更新して返す
foreach (Pair pair in buckets[index]) {
if (pair.key == key) {
pair.val = val;
return;
}
}
// その key が存在しなければ、キーと値のペアを末尾に追加
buckets[index].Add(new Pair(key, val));
size++;
}
/* 削除操作 */
public void Remove(int key) {
int index = HashFunc(key);
// バケットを走査してキーと値のペアを削除
foreach (Pair pair in buckets[index].ToList()) {
if (pair.key == key) {
buckets[index].Remove(pair);
size--;
break;
}
}
}
/* ハッシュテーブルを拡張 */
void Extend() {
// 元のハッシュテーブルを一時保存
List<List<Pair>> bucketsTmp = buckets;
// リサイズ後の新しいハッシュテーブルを初期化
capacity *= extendRatio;
buckets = new List<List<Pair>>(capacity);
for (int i = 0; i < capacity; i++) {
buckets.Add([]);
}
size = 0;
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
foreach (List<Pair> bucket in bucketsTmp) {
foreach (Pair pair in bucket) {
Put(pair.key, pair.val);
}
}
}
/* ハッシュテーブルを出力 */
public void Print() {
foreach (List<Pair> bucket in buckets) {
List<string> res = [];
foreach (Pair pair in bucket) {
res.Add(pair.key + " -> " + pair.val);
}
foreach (string kv in res) {
Console.WriteLine(kv);
}
}
}
}
/* チェイン法ハッシュテーブル */
type hashMapChaining struct {
size int // キーと値のペア数
capacity int // ハッシュテーブル容量
loadThres float64 // リサイズを発動する負荷率のしきい値
extendRatio int // 拡張倍率
buckets [][]pair // バケット配列
}
/* コンストラクタ */
func newHashMapChaining() *hashMapChaining {
buckets := make([][]pair, 4)
for i := 0; i < 4; i++ {
buckets[i] = make([]pair, 0)
}
return &hashMapChaining{
size: 0,
capacity: 4,
loadThres: 2.0 / 3.0,
extendRatio: 2,
buckets: buckets,
}
}
/* ハッシュ関数 */
func (m *hashMapChaining) hashFunc(key int) int {
return key % m.capacity
}
/* 負荷率 */
func (m *hashMapChaining) loadFactor() float64 {
return float64(m.size) / float64(m.capacity)
}
/* 検索操作 */
func (m *hashMapChaining) get(key int) string {
idx := m.hashFunc(key)
bucket := m.buckets[idx]
// バケットを走査し、key が見つかれば対応する val を返す
for _, p := range bucket {
if p.key == key {
return p.val
}
}
// key が見つからない場合は空文字列を返す
return ""
}
/* 追加操作 */
func (m *hashMapChaining) put(key int, val string) {
// 負荷率がしきい値を超えたら、リサイズを実行
if m.loadFactor() > m.loadThres {
m.extend()
}
idx := m.hashFunc(key)
// バケットを走査し、指定した key が見つかれば対応する val を更新して返す
for i := range m.buckets[idx] {
if m.buckets[idx][i].key == key {
m.buckets[idx][i].val = val
return
}
}
// その key が存在しなければ、キーと値のペアを末尾に追加
p := pair{
key: key,
val: val,
}
m.buckets[idx] = append(m.buckets[idx], p)
m.size += 1
}
/* 削除操作 */
func (m *hashMapChaining) remove(key int) {
idx := m.hashFunc(key)
// バケットを走査してキーと値のペアを削除
for i, p := range m.buckets[idx] {
if p.key == key {
// スライスから削除する
m.buckets[idx] = append(m.buckets[idx][:i], m.buckets[idx][i+1:]...)
m.size -= 1
break
}
}
}
/* ハッシュテーブルを拡張 */
func (m *hashMapChaining) extend() {
// 元のハッシュテーブルを一時保存
tmpBuckets := make([][]pair, len(m.buckets))
for i := 0; i < len(m.buckets); i++ {
tmpBuckets[i] = make([]pair, len(m.buckets[i]))
copy(tmpBuckets[i], m.buckets[i])
}
// リサイズ後の新しいハッシュテーブルを初期化
m.capacity *= m.extendRatio
m.buckets = make([][]pair, m.capacity)
for i := 0; i < m.capacity; i++ {
m.buckets[i] = make([]pair, 0)
}
m.size = 0
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for _, bucket := range tmpBuckets {
for _, p := range bucket {
m.put(p.key, p.val)
}
}
}
/* ハッシュテーブルを出力 */
func (m *hashMapChaining) print() {
var builder strings.Builder
for _, bucket := range m.buckets {
builder.WriteString("[")
for _, p := range bucket {
builder.WriteString(strconv.Itoa(p.key) + " -> " + p.val + " ")
}
builder.WriteString("]")
fmt.Println(builder.String())
builder.Reset()
}
}
/* チェイン法ハッシュテーブル */
class HashMapChaining {
var size: Int // キーと値のペア数
var capacity: Int // ハッシュテーブル容量
var loadThres: Double // リサイズを発動する負荷率のしきい値
var extendRatio: Int // 拡張倍率
var buckets: [[Pair]] // バケット配列
/* コンストラクタ */
init() {
size = 0
capacity = 4
loadThres = 2.0 / 3.0
extendRatio = 2
buckets = Array(repeating: [], count: capacity)
}
/* ハッシュ関数 */
func hashFunc(key: Int) -> Int {
key % capacity
}
/* 負荷率 */
func loadFactor() -> Double {
Double(size) / Double(capacity)
}
/* 検索操作 */
func get(key: Int) -> String? {
let index = hashFunc(key: key)
let bucket = buckets[index]
// バケットを走査し、key が見つかれば対応する val を返す
for pair in bucket {
if pair.key == key {
return pair.val
}
}
// `key` が見つからなければ `nil` を返す
return nil
}
/* 追加操作 */
func put(key: Int, val: String) {
// 負荷率がしきい値を超えたら、リサイズを実行
if loadFactor() > loadThres {
extend()
}
let index = hashFunc(key: key)
let bucket = buckets[index]
// バケットを走査し、指定した key が見つかれば対応する val を更新して返す
for pair in bucket {
if pair.key == key {
pair.val = val
return
}
}
// その key が存在しなければ、キーと値のペアを末尾に追加
let pair = Pair(key: key, val: val)
buckets[index].append(pair)
size += 1
}
/* 削除操作 */
func remove(key: Int) {
let index = hashFunc(key: key)
let bucket = buckets[index]
// バケットを走査してキーと値のペアを削除
for (pairIndex, pair) in bucket.enumerated() {
if pair.key == key {
buckets[index].remove(at: pairIndex)
size -= 1
break
}
}
}
/* ハッシュテーブルを拡張 */
func extend() {
// 元のハッシュテーブルを一時保存
let bucketsTmp = buckets
// リサイズ後の新しいハッシュテーブルを初期化
capacity *= extendRatio
buckets = Array(repeating: [], count: capacity)
size = 0
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for bucket in bucketsTmp {
for pair in bucket {
put(key: pair.key, val: pair.val)
}
}
}
/* ハッシュテーブルを出力 */
func print() {
for bucket in buckets {
let res = bucket.map { "\($0.key) -> \($0.val)" }
Swift.print(res)
}
}
}
/* チェイン法ハッシュテーブル */
class HashMapChaining {
#size; // キーと値のペア数
#capacity; // ハッシュテーブル容量
#loadThres; // リサイズを発動する負荷率のしきい値
#extendRatio; // 拡張倍率
#buckets; // バケット配列
/* コンストラクタ */
constructor() {
this.#size = 0;
this.#capacity = 4;
this.#loadThres = 2.0 / 3.0;
this.#extendRatio = 2;
this.#buckets = new Array(this.#capacity).fill(null).map((x) => []);
}
/* ハッシュ関数 */
#hashFunc(key) {
return key % this.#capacity;
}
/* 負荷率 */
#loadFactor() {
return this.#size / this.#capacity;
}
/* 検索操作 */
get(key) {
const index = this.#hashFunc(key);
const bucket = this.#buckets[index];
// バケットを走査し、key が見つかれば対応する val を返す
for (const pair of bucket) {
if (pair.key === key) {
return pair.val;
}
}
// key が見つからない場合は null を返す
return null;
}
/* 追加操作 */
put(key, val) {
// 負荷率がしきい値を超えたら、リサイズを実行
if (this.#loadFactor() > this.#loadThres) {
this.#extend();
}
const index = this.#hashFunc(key);
const bucket = this.#buckets[index];
// バケットを走査し、指定した key が見つかれば対応する val を更新して返す
for (const pair of bucket) {
if (pair.key === key) {
pair.val = val;
return;
}
}
// その key が存在しなければ、キーと値のペアを末尾に追加
const pair = new Pair(key, val);
bucket.push(pair);
this.#size++;
}
/* 削除操作 */
remove(key) {
const index = this.#hashFunc(key);
let bucket = this.#buckets[index];
// バケットを走査してキーと値のペアを削除
for (let i = 0; i < bucket.length; i++) {
if (bucket[i].key === key) {
bucket.splice(i, 1);
this.#size--;
break;
}
}
}
/* ハッシュテーブルを拡張 */
#extend() {
// 元のハッシュテーブルを一時保存
const bucketsTmp = this.#buckets;
// リサイズ後の新しいハッシュテーブルを初期化
this.#capacity *= this.#extendRatio;
this.#buckets = new Array(this.#capacity).fill(null).map((x) => []);
this.#size = 0;
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for (const bucket of bucketsTmp) {
for (const pair of bucket) {
this.put(pair.key, pair.val);
}
}
}
/* ハッシュテーブルを出力 */
print() {
for (const bucket of this.#buckets) {
let res = [];
for (const pair of bucket) {
res.push(pair.key + ' -> ' + pair.val);
}
console.log(res);
}
}
}
/* チェイン法ハッシュテーブル */
class HashMapChaining {
#size: number; // キーと値のペア数
#capacity: number; // ハッシュテーブル容量
#loadThres: number; // リサイズを発動する負荷率のしきい値
#extendRatio: number; // 拡張倍率
#buckets: Pair[][]; // バケット配列
/* コンストラクタ */
constructor() {
this.#size = 0;
this.#capacity = 4;
this.#loadThres = 2.0 / 3.0;
this.#extendRatio = 2;
this.#buckets = new Array(this.#capacity).fill(null).map((x) => []);
}
/* ハッシュ関数 */
#hashFunc(key: number): number {
return key % this.#capacity;
}
/* 負荷率 */
#loadFactor(): number {
return this.#size / this.#capacity;
}
/* 検索操作 */
get(key: number): string | null {
const index = this.#hashFunc(key);
const bucket = this.#buckets[index];
// バケットを走査し、key が見つかれば対応する val を返す
for (const pair of bucket) {
if (pair.key === key) {
return pair.val;
}
}
// key が見つからない場合は null を返す
return null;
}
/* 追加操作 */
put(key: number, val: string): void {
// 負荷率がしきい値を超えたら、リサイズを実行
if (this.#loadFactor() > this.#loadThres) {
this.#extend();
}
const index = this.#hashFunc(key);
const bucket = this.#buckets[index];
// バケットを走査し、指定した key が見つかれば対応する val を更新して返す
for (const pair of bucket) {
if (pair.key === key) {
pair.val = val;
return;
}
}
// その key が存在しなければ、キーと値のペアを末尾に追加
const pair = new Pair(key, val);
bucket.push(pair);
this.#size++;
}
/* 削除操作 */
remove(key: number): void {
const index = this.#hashFunc(key);
let bucket = this.#buckets[index];
// バケットを走査してキーと値のペアを削除
for (let i = 0; i < bucket.length; i++) {
if (bucket[i].key === key) {
bucket.splice(i, 1);
this.#size--;
break;
}
}
}
/* ハッシュテーブルを拡張 */
#extend(): void {
// 元のハッシュテーブルを一時保存
const bucketsTmp = this.#buckets;
// リサイズ後の新しいハッシュテーブルを初期化
this.#capacity *= this.#extendRatio;
this.#buckets = new Array(this.#capacity).fill(null).map((x) => []);
this.#size = 0;
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for (const bucket of bucketsTmp) {
for (const pair of bucket) {
this.put(pair.key, pair.val);
}
}
}
/* ハッシュテーブルを出力 */
print(): void {
for (const bucket of this.#buckets) {
let res = [];
for (const pair of bucket) {
res.push(pair.key + ' -> ' + pair.val);
}
console.log(res);
}
}
}
/* チェイン法ハッシュテーブル */
class HashMapChaining {
late int size; // キーと値のペア数
late int capacity; // ハッシュテーブル容量
late double loadThres; // リサイズを発動する負荷率のしきい値
late int extendRatio; // 拡張倍率
late List<List<Pair>> buckets; // バケット配列
/* コンストラクタ */
HashMapChaining() {
size = 0;
capacity = 4;
loadThres = 2.0 / 3.0;
extendRatio = 2;
buckets = List.generate(capacity, (_) => []);
}
/* ハッシュ関数 */
int hashFunc(int key) {
return key % capacity;
}
/* 負荷率 */
double loadFactor() {
return size / capacity;
}
/* 検索操作 */
String? get(int key) {
int index = hashFunc(key);
List<Pair> bucket = buckets[index];
// バケットを走査し、key が見つかれば対応する val を返す
for (Pair pair in bucket) {
if (pair.key == key) {
return pair.val;
}
}
// key が見つからない場合は null を返す
return null;
}
/* 追加操作 */
void put(int key, String val) {
// 負荷率がしきい値を超えたら、リサイズを実行
if (loadFactor() > loadThres) {
extend();
}
int index = hashFunc(key);
List<Pair> bucket = buckets[index];
// バケットを走査し、指定した key が見つかれば対応する val を更新して返す
for (Pair pair in bucket) {
if (pair.key == key) {
pair.val = val;
return;
}
}
// その key が存在しなければ、キーと値のペアを末尾に追加
Pair pair = Pair(key, val);
bucket.add(pair);
size++;
}
/* 削除操作 */
void remove(int key) {
int index = hashFunc(key);
List<Pair> bucket = buckets[index];
// バケットを走査してキーと値のペアを削除
for (Pair pair in bucket) {
if (pair.key == key) {
bucket.remove(pair);
size--;
break;
}
}
}
/* ハッシュテーブルを拡張 */
void extend() {
// 元のハッシュテーブルを一時保存
List<List<Pair>> bucketsTmp = buckets;
// リサイズ後の新しいハッシュテーブルを初期化
capacity *= extendRatio;
buckets = List.generate(capacity, (_) => []);
size = 0;
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for (List<Pair> bucket in bucketsTmp) {
for (Pair pair in bucket) {
put(pair.key, pair.val);
}
}
}
/* ハッシュテーブルを出力 */
void printHashMap() {
for (List<Pair> bucket in buckets) {
List<String> res = [];
for (Pair pair in bucket) {
res.add("${pair.key} -> ${pair.val}");
}
print(res);
}
}
}
/* チェイン法ハッシュテーブル */
struct HashMapChaining {
size: usize,
capacity: usize,
load_thres: f32,
extend_ratio: usize,
buckets: Vec<Vec<Pair>>,
}
impl HashMapChaining {
/* コンストラクタ */
fn new() -> Self {
Self {
size: 0,
capacity: 4,
load_thres: 2.0 / 3.0,
extend_ratio: 2,
buckets: vec![vec![]; 4],
}
}
/* ハッシュ関数 */
fn hash_func(&self, key: i32) -> usize {
key as usize % self.capacity
}
/* 負荷率 */
fn load_factor(&self) -> f32 {
self.size as f32 / self.capacity as f32
}
/* 削除操作 */
fn remove(&mut self, key: i32) -> Option<String> {
let index = self.hash_func(key);
// バケットを走査してキーと値のペアを削除
for (i, p) in self.buckets[index].iter_mut().enumerate() {
if p.key == key {
let pair = self.buckets[index].remove(i);
self.size -= 1;
return Some(pair.val);
}
}
// key が見つからない場合は None を返す
None
}
/* ハッシュテーブルを拡張 */
fn extend(&mut self) {
// 元のハッシュテーブルを一時保存
let buckets_tmp = std::mem::take(&mut self.buckets);
// リサイズ後の新しいハッシュテーブルを初期化
self.capacity *= self.extend_ratio;
self.buckets = vec![Vec::new(); self.capacity as usize];
self.size = 0;
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for bucket in buckets_tmp {
for pair in bucket {
self.put(pair.key, pair.val);
}
}
}
/* ハッシュテーブルを出力 */
fn print(&self) {
for bucket in &self.buckets {
let mut res = Vec::new();
for pair in bucket {
res.push(format!("{} -> {}", pair.key, pair.val));
}
println!("{:?}", res);
}
}
/* 追加操作 */
fn put(&mut self, key: i32, val: String) {
// 負荷率がしきい値を超えたら、リサイズを実行
if self.load_factor() > self.load_thres {
self.extend();
}
let index = self.hash_func(key);
// バケットを走査し、指定した key が見つかれば対応する val を更新して返す
for pair in self.buckets[index].iter_mut() {
if pair.key == key {
pair.val = val;
return;
}
}
// その key が存在しなければ、キーと値のペアを末尾に追加
let pair = Pair { key, val };
self.buckets[index].push(pair);
self.size += 1;
}
/* 検索操作 */
fn get(&self, key: i32) -> Option<&str> {
let index = self.hash_func(key);
// バケットを走査し、key が見つかれば対応する val を返す
for pair in self.buckets[index].iter() {
if pair.key == key {
return Some(&pair.val);
}
}
// key が見つからない場合は None を返す
None
}
}
/* 連結リストノード */
typedef struct Node {
Pair *pair;
struct Node *next;
} Node;
/* チェイン法ハッシュテーブル */
typedef struct {
int size; // キーと値のペア数
int capacity; // ハッシュテーブル容量
double loadThres; // リサイズを発動する負荷率のしきい値
int extendRatio; // 拡張倍率
Node **buckets; // バケット配列
} HashMapChaining;
/* コンストラクタ */
HashMapChaining *newHashMapChaining() {
HashMapChaining *hashMap = (HashMapChaining *)malloc(sizeof(HashMapChaining));
hashMap->size = 0;
hashMap->capacity = 4;
hashMap->loadThres = 2.0 / 3.0;
hashMap->extendRatio = 2;
hashMap->buckets = (Node **)malloc(hashMap->capacity * sizeof(Node *));
for (int i = 0; i < hashMap->capacity; i++) {
hashMap->buckets[i] = NULL;
}
return hashMap;
}
/* デストラクタ */
void delHashMapChaining(HashMapChaining *hashMap) {
for (int i = 0; i < hashMap->capacity; i++) {
Node *cur = hashMap->buckets[i];
while (cur) {
Node *tmp = cur;
cur = cur->next;
free(tmp->pair);
free(tmp);
}
}
free(hashMap->buckets);
free(hashMap);
}
/* ハッシュ関数 */
int hashFunc(HashMapChaining *hashMap, int key) {
return key % hashMap->capacity;
}
/* 負荷率 */
double loadFactor(HashMapChaining *hashMap) {
return (double)hashMap->size / (double)hashMap->capacity;
}
/* 検索操作 */
char *get(HashMapChaining *hashMap, int key) {
int index = hashFunc(hashMap, key);
// バケットを走査し、key が見つかれば対応する val を返す
Node *cur = hashMap->buckets[index];
while (cur) {
if (cur->pair->key == key) {
return cur->pair->val;
}
cur = cur->next;
}
return ""; // key が見つからない場合は空文字列を返す
}
/* 追加操作 */
void put(HashMapChaining *hashMap, int key, const char *val) {
// 負荷率がしきい値を超えたら、リサイズを実行
if (loadFactor(hashMap) > hashMap->loadThres) {
extend(hashMap);
}
int index = hashFunc(hashMap, key);
// バケットを走査し、指定した key が見つかれば対応する val を更新して返す
Node *cur = hashMap->buckets[index];
while (cur) {
if (cur->pair->key == key) {
strcpy(cur->pair->val, val); // 指定した `key` に遭遇したら、対応する `val` を更新して返す
return;
}
cur = cur->next;
}
// 該当する `key` がなければ、キーと値のペアを連結リストの先頭に追加する
Pair *newPair = (Pair *)malloc(sizeof(Pair));
newPair->key = key;
strcpy(newPair->val, val);
Node *newNode = (Node *)malloc(sizeof(Node));
newNode->pair = newPair;
newNode->next = hashMap->buckets[index];
hashMap->buckets[index] = newNode;
hashMap->size++;
}
/* ハッシュテーブルを拡張 */
void extend(HashMapChaining *hashMap) {
// 元のハッシュテーブルを一時保存
int oldCapacity = hashMap->capacity;
Node **oldBuckets = hashMap->buckets;
// リサイズ後の新しいハッシュテーブルを初期化
hashMap->capacity *= hashMap->extendRatio;
hashMap->buckets = (Node **)malloc(hashMap->capacity * sizeof(Node *));
for (int i = 0; i < hashMap->capacity; i++) {
hashMap->buckets[i] = NULL;
}
hashMap->size = 0;
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for (int i = 0; i < oldCapacity; i++) {
Node *cur = oldBuckets[i];
while (cur) {
put(hashMap, cur->pair->key, cur->pair->val);
Node *temp = cur;
cur = cur->next;
// メモリを解放する
free(temp->pair);
free(temp);
}
}
free(oldBuckets);
}
/* 削除操作 */
void removeItem(HashMapChaining *hashMap, int key) {
int index = hashFunc(hashMap, key);
Node *cur = hashMap->buckets[index];
Node *pre = NULL;
while (cur) {
if (cur->pair->key == key) {
// そこからキーと値の組を削除する
if (pre) {
pre->next = cur->next;
} else {
hashMap->buckets[index] = cur->next;
}
// メモリを解放する
free(cur->pair);
free(cur);
hashMap->size--;
return;
}
pre = cur;
cur = cur->next;
}
}
/* ハッシュテーブルを出力 */
void print(HashMapChaining *hashMap) {
for (int i = 0; i < hashMap->capacity; i++) {
Node *cur = hashMap->buckets[i];
printf("[");
while (cur) {
printf("%d -> %s, ", cur->pair->key, cur->pair->val);
cur = cur->next;
}
printf("]\n");
}
}
/* チェイン法ハッシュテーブル */
class HashMapChaining {
var size: Int // キーと値のペア数
var capacity: Int // ハッシュテーブル容量
val loadThres: Double // リサイズを発動する負荷率のしきい値
val extendRatio: Int // 拡張倍率
var buckets: MutableList<MutableList<Pair>> // バケット配列
/* コンストラクタ */
init {
size = 0
capacity = 4
loadThres = 2.0 / 3.0
extendRatio = 2
buckets = mutableListOf()
for (i in 0..<capacity) {
buckets.add(mutableListOf())
}
}
/* ハッシュ関数 */
fun hashFunc(key: Int): Int {
return key % capacity
}
/* 負荷率 */
fun loadFactor(): Double {
return (size / capacity).toDouble()
}
/* 検索操作 */
fun get(key: Int): String? {
val index = hashFunc(key)
val bucket = buckets[index]
// バケットを走査し、key が見つかれば対応する val を返す
for (pair in bucket) {
if (pair.key == key) return pair._val
}
// key が見つからない場合は null を返す
return null
}
/* 追加操作 */
fun put(key: Int, _val: String) {
// 負荷率がしきい値を超えたら、リサイズを実行
if (loadFactor() > loadThres) {
extend()
}
val index = hashFunc(key)
val bucket = buckets[index]
// バケットを走査し、指定した key が見つかれば対応する val を更新して返す
for (pair in bucket) {
if (pair.key == key) {
pair._val = _val
return
}
}
// その key が存在しなければ、キーと値のペアを末尾に追加
val pair = Pair(key, _val)
bucket.add(pair)
size++
}
/* 削除操作 */
fun remove(key: Int) {
val index = hashFunc(key)
val bucket = buckets[index]
// バケットを走査してキーと値のペアを削除
for (pair in bucket) {
if (pair.key == key) {
bucket.remove(pair)
size--
break
}
}
}
/* ハッシュテーブルを拡張 */
fun extend() {
// 元のハッシュテーブルを一時保存
val bucketsTmp = buckets
// リサイズ後の新しいハッシュテーブルを初期化
capacity *= extendRatio
// mutablelist には固定サイズがない
buckets = mutableListOf()
for (i in 0..<capacity) {
buckets.add(mutableListOf())
}
size = 0
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for (bucket in bucketsTmp) {
for (pair in bucket) {
put(pair.key, pair._val)
}
}
}
/* ハッシュテーブルを出力 */
fun print() {
for (bucket in buckets) {
val res = mutableListOf<String>()
for (pair in bucket) {
val k = pair.key
val v = pair._val
res.add("$k -> $v")
}
println(res)
}
}
}
### キーアドレス法ハッシュテーブル ###
class HashMapChaining
### コンストラクタ ###
def initialize
@size = 0 # キーと値のペア数
@capacity = 4 # ハッシュテーブル容量
@load_thres = 2.0 / 3.0 # リサイズを発動する負荷率のしきい値
@extend_ratio = 2 # 拡張倍率
@buckets = Array.new(@capacity) { [] } # バケット配列
end
### ハッシュ関数 ###
def hash_func(key)
key % @capacity
end
### 負荷率 ###
def load_factor
@size / @capacity
end
### 検索操作 ###
def get(key)
index = hash_func(key)
bucket = @buckets[index]
# バケットを走査し、key が見つかれば対応する val を返す
for pair in bucket
return pair.val if pair.key == key
end
# `key` が見つからなければ `nil` を返す
nil
end
### 追加操作 ###
def put(key, val)
# 負荷率がしきい値を超えたら、リサイズを実行
extend if load_factor > @load_thres
index = hash_func(key)
bucket = @buckets[index]
# バケットを走査し、指定した key が見つかれば対応する val を更新して返す
for pair in bucket
if pair.key == key
pair.val = val
return
end
end
# その key が存在しなければ、キーと値のペアを末尾に追加
pair = Pair.new(key, val)
bucket << pair
@size += 1
end
### 削除操作 ###
def remove(key)
index = hash_func(key)
bucket = @buckets[index]
# バケットを走査してキーと値のペアを削除
for pair in bucket
if pair.key == key
bucket.delete(pair)
@size -= 1
break
end
end
end
### ハッシュテーブルを拡張 ###
def extend
# 元のハッシュテーブルを一時保存
buckets = @buckets
# リサイズ後の新しいハッシュテーブルを初期化
@capacity *= @extend_ratio
@buckets = Array.new(@capacity) { [] }
@size = 0
# キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for bucket in buckets
for pair in bucket
put(pair.key, pair.val)
end
end
end
### ハッシュテーブルを出力 ###
def print
for bucket in @buckets
res = []
for pair in bucket
res << "#{pair.key} -> #{pair.val}"
end
pp res
end
end
end
コードの可視化
注意すべきなのは、連結リストが長い場合、検索効率 \(O(n)\) は非常に低いことです。このとき、連結リストを「AVL 木」または「赤黒木」に変換することで、検索操作の時間計算量を \(O(\log n)\) に最適化できます。
6.2.2 オープンアドレッシング¶
オープンアドレッシング(open addressing)では追加のデータ構造を導入せず、「複数回の探索」によってハッシュ衝突を処理します。探索方法には主に線形探索、二次探索、多重ハッシュなどがあります。
以下では線形探索を例に、オープンアドレッシングハッシュテーブルの動作の仕組みを説明します。
1. 線形探索¶
線形探索では、固定ステップ長の線形探索によって探索を行います。その操作方法は通常のハッシュテーブルとは異なります。
- 要素の挿入:ハッシュ関数によってバケットインデックスを計算し、バケット内にすでに要素がある場合は、衝突位置から後方へ線形に走査し(ステップ長は通常 \(1\) )、空のバケットが見つかるまで進み、その中に要素を挿入します。
- 要素の検索:ハッシュ衝突が見つかった場合は、同じステップ長で後方へ線形走査を行い、対応する要素が見つかるまで続け、
valueを返します。空のバケットに遭遇した場合は、対象要素がハッシュテーブル内に存在しないことを意味するため、Noneを返します。
下図はオープンアドレッシング(線形探索)ハッシュテーブルにおけるキーと値のペアの分布を示しています。このハッシュ関数では、末尾 2 桁が同じ key はすべて同じバケットに写像されます。線形探索によって、それらはそのバケットとその後続のバケットに順に格納されます。

図 6-6 オープンアドレッシング(線形探索)ハッシュテーブルにおけるキーと値のペアの分布
しかし、**線形探索では「クラスタリング現象」が起こりやすい**です。具体的には、配列内で連続して占有された位置が長いほど、それらの連続位置でハッシュ衝突が発生する可能性が高くなり、さらにその位置の集積成長を促して悪循環を生み、最終的には追加・削除・検索・更新操作の効率低下を招きます。
注意すべきなのは、**オープンアドレッシングハッシュテーブルでは要素を直接削除できない**ことです。これは、要素を削除すると配列内に空バケット None が生じ、要素を検索するときに線形探索がその空バケットに到達した時点で返ってしまうため、その空バケットより後ろの要素には二度とアクセスできなくなるからです。結果として、プログラムがそれらの要素を存在しないと誤判定する可能性があります。下図のとおりです。

図 6-7 オープンアドレッシングで要素を削除したことによる検索問題
この問題を解決するために、遅延削除(lazy deletion)の仕組みを採用できます。これは要素をハッシュテーブルから直接取り除かず、代わりに定数 TOMBSTONE を使ってこのバケットをマークします。この仕組みでは、None と TOMBSTONE はどちらも空バケットを表し、どちらにもキーと値のペアを配置できます。ただし異なるのは、線形探索が TOMBSTONE に到達した場合は、その先にキーと値のペアが存在する可能性があるため、探索を続けるべきだという点です。
しかし、遅延削除はハッシュテーブルの性能劣化を加速させる可能性があります。これは、削除操作のたびに削除マークが 1 つ生成され、TOMBSTONE が増えるにつれて探索時間も増加するためです。線形探索では、対象要素を見つけるまでに複数の TOMBSTONE を飛び越える必要があるかもしれません。
そのため、線形探索では、遭遇した最初の TOMBSTONE のインデックスを記録し、見つかった対象要素とその TOMBSTONE を交換することを考えます。こうする利点は、要素を検索または追加するたびに、要素が理想位置(探索開始点)により近いバケットへ移動し、検索効率が向上することです。
以下のコードは、遅延削除を含むオープンアドレッシング(線形探索)ハッシュテーブルを実装したものです。ハッシュテーブルの空間をより十分に活用するために、ハッシュテーブルを「環状配列」とみなし、配列末尾を越えたら先頭に戻って探索を続けます。
class HashMapOpenAddressing:
"""オープンアドレス法ハッシュテーブル"""
def __init__(self):
"""コンストラクタ"""
self.size = 0 # キーと値のペア数
self.capacity = 4 # ハッシュテーブル容量
self.load_thres = 2.0 / 3.0 # リサイズを発動する負荷率のしきい値
self.extend_ratio = 2 # 拡張倍率
self.buckets: list[Pair | None] = [None] * self.capacity # バケット配列
self.TOMBSTONE = Pair(-1, "-1") # 削除済みマーク
def hash_func(self, key: int) -> int:
"""ハッシュ関数"""
return key % self.capacity
def load_factor(self) -> float:
"""負荷率"""
return self.size / self.capacity
def find_bucket(self, key: int) -> int:
"""key に対応するバケットインデックスを探す"""
index = self.hash_func(key)
first_tombstone = -1
# 線形プロービングを行い、空バケットに達したら終了
while self.buckets[index] is not None:
# key が見つかったら、対応するバケットのインデックスを返す
if self.buckets[index].key == key:
# 以前に削除マークが見つかっていれば、そのインデックスへキーと値のペアを移動
if first_tombstone != -1:
self.buckets[first_tombstone] = self.buckets[index]
self.buckets[index] = self.TOMBSTONE
return first_tombstone # 移動後のバケットインデックスを返す
return index # バケットのインデックスを返す
# 最初に見つかった削除マークを記録
if first_tombstone == -1 and self.buckets[index] is self.TOMBSTONE:
first_tombstone = index
# バケットのインデックスを計算し、末尾を越えたら先頭に戻る
index = (index + 1) % self.capacity
# key が存在しない場合は追加位置のインデックスを返す
return index if first_tombstone == -1 else first_tombstone
def get(self, key: int) -> str:
"""検索操作"""
# key に対応するバケットインデックスを探す
index = self.find_bucket(key)
# キーと値の組が見つかったら、対応する val を返す
if self.buckets[index] not in [None, self.TOMBSTONE]:
return self.buckets[index].val
# キーと値のペアが存在しない場合は `None` を返す
return None
def put(self, key: int, val: str):
"""追加操作"""
# 負荷率がしきい値を超えたら、リサイズを実行
if self.load_factor() > self.load_thres:
self.extend()
# key に対応するバケットインデックスを探す
index = self.find_bucket(key)
# キーと値の組が見つかったら、val を上書きして返す
if self.buckets[index] not in [None, self.TOMBSTONE]:
self.buckets[index].val = val
return
# キーと値の組が存在しない場合は、その組を追加する
self.buckets[index] = Pair(key, val)
self.size += 1
def remove(self, key: int):
"""削除操作"""
# key に対応するバケットインデックスを探す
index = self.find_bucket(key)
# キーと値の組が見つかったら、削除マーカーで上書きする
if self.buckets[index] not in [None, self.TOMBSTONE]:
self.buckets[index] = self.TOMBSTONE
self.size -= 1
def extend(self):
"""ハッシュテーブルを拡張"""
# 元のハッシュテーブルを一時保存
buckets_tmp = self.buckets
# リサイズ後の新しいハッシュテーブルを初期化
self.capacity *= self.extend_ratio
self.buckets = [None] * self.capacity
self.size = 0
# キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for pair in buckets_tmp:
if pair not in [None, self.TOMBSTONE]:
self.put(pair.key, pair.val)
def print(self):
"""ハッシュテーブルを出力"""
for pair in self.buckets:
if pair is None:
print("None")
elif pair is self.TOMBSTONE:
print("TOMBSTONE")
else:
print(pair.key, "->", pair.val)
/* オープンアドレス法ハッシュテーブル */
class HashMapOpenAddressing {
private:
int size; // キーと値のペア数
int capacity = 4; // ハッシュテーブル容量
const double loadThres = 2.0 / 3.0; // リサイズを発動する負荷率のしきい値
const int extendRatio = 2; // 拡張倍率
vector<Pair *> buckets; // バケット配列
Pair *TOMBSTONE = new Pair(-1, "-1"); // 削除済みマーク
public:
/* コンストラクタ */
HashMapOpenAddressing() : size(0), buckets(capacity, nullptr) {
}
/* デストラクタメソッド */
~HashMapOpenAddressing() {
for (Pair *pair : buckets) {
if (pair != nullptr && pair != TOMBSTONE) {
delete pair;
}
}
delete TOMBSTONE;
}
/* ハッシュ関数 */
int hashFunc(int key) {
return key % capacity;
}
/* 負荷率 */
double loadFactor() {
return (double)size / capacity;
}
/* key に対応するバケットインデックスを探す */
int findBucket(int key) {
int index = hashFunc(key);
int firstTombstone = -1;
// 線形プロービングを行い、空バケットに達したら終了
while (buckets[index] != nullptr) {
// key が見つかったら、対応するバケットのインデックスを返す
if (buckets[index]->key == key) {
// 以前に削除マークが見つかっていれば、そのインデックスへキーと値のペアを移動
if (firstTombstone != -1) {
buckets[firstTombstone] = buckets[index];
buckets[index] = TOMBSTONE;
return firstTombstone; // 移動後のバケットインデックスを返す
}
return index; // バケットのインデックスを返す
}
// 最初に見つかった削除マークを記録
if (firstTombstone == -1 && buckets[index] == TOMBSTONE) {
firstTombstone = index;
}
// バケットのインデックスを計算し、末尾を越えたら先頭に戻る
index = (index + 1) % capacity;
}
// key が存在しない場合は追加位置のインデックスを返す
return firstTombstone == -1 ? index : firstTombstone;
}
/* 検索操作 */
string get(int key) {
// key に対応するバケットインデックスを探す
int index = findBucket(key);
// キーと値の組が見つかったら、対応する val を返す
if (buckets[index] != nullptr && buckets[index] != TOMBSTONE) {
return buckets[index]->val;
}
// キーと値の組が存在しない場合は空文字列を返す
return "";
}
/* 追加操作 */
void put(int key, string val) {
// 負荷率がしきい値を超えたら、リサイズを実行
if (loadFactor() > loadThres) {
extend();
}
// key に対応するバケットインデックスを探す
int index = findBucket(key);
// キーと値の組が見つかったら、val を上書きして返す
if (buckets[index] != nullptr && buckets[index] != TOMBSTONE) {
buckets[index]->val = val;
return;
}
// キーと値の組が存在しない場合は、その組を追加する
buckets[index] = new Pair(key, val);
size++;
}
/* 削除操作 */
void remove(int key) {
// key に対応するバケットインデックスを探す
int index = findBucket(key);
// キーと値の組が見つかったら、削除マーカーで上書きする
if (buckets[index] != nullptr && buckets[index] != TOMBSTONE) {
delete buckets[index];
buckets[index] = TOMBSTONE;
size--;
}
}
/* ハッシュテーブルを拡張 */
void extend() {
// 元のハッシュテーブルを一時保存
vector<Pair *> bucketsTmp = buckets;
// リサイズ後の新しいハッシュテーブルを初期化
capacity *= extendRatio;
buckets = vector<Pair *>(capacity, nullptr);
size = 0;
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for (Pair *pair : bucketsTmp) {
if (pair != nullptr && pair != TOMBSTONE) {
put(pair->key, pair->val);
delete pair;
}
}
}
/* ハッシュテーブルを出力 */
void print() {
for (Pair *pair : buckets) {
if (pair == nullptr) {
cout << "nullptr" << endl;
} else if (pair == TOMBSTONE) {
cout << "TOMBSTONE" << endl;
} else {
cout << pair->key << " -> " << pair->val << endl;
}
}
}
};
/* オープンアドレス法ハッシュテーブル */
class HashMapOpenAddressing {
private int size; // キーと値のペア数
private int capacity = 4; // ハッシュテーブル容量
private final double loadThres = 2.0 / 3.0; // リサイズを発動する負荷率のしきい値
private final int extendRatio = 2; // 拡張倍率
private Pair[] buckets; // バケット配列
private final Pair TOMBSTONE = new Pair(-1, "-1"); // 削除済みマーク
/* コンストラクタ */
public HashMapOpenAddressing() {
size = 0;
buckets = new Pair[capacity];
}
/* ハッシュ関数 */
private int hashFunc(int key) {
return key % capacity;
}
/* 負荷率 */
private double loadFactor() {
return (double) size / capacity;
}
/* key に対応するバケットインデックスを探す */
private int findBucket(int key) {
int index = hashFunc(key);
int firstTombstone = -1;
// 線形プロービングを行い、空バケットに達したら終了
while (buckets[index] != null) {
// key が見つかったら、対応するバケットのインデックスを返す
if (buckets[index].key == key) {
// 以前に削除マークが見つかっていれば、そのインデックスへキーと値のペアを移動
if (firstTombstone != -1) {
buckets[firstTombstone] = buckets[index];
buckets[index] = TOMBSTONE;
return firstTombstone; // 移動後のバケットインデックスを返す
}
return index; // バケットのインデックスを返す
}
// 最初に見つかった削除マークを記録
if (firstTombstone == -1 && buckets[index] == TOMBSTONE) {
firstTombstone = index;
}
// バケットのインデックスを計算し、末尾を越えたら先頭に戻る
index = (index + 1) % capacity;
}
// key が存在しない場合は追加位置のインデックスを返す
return firstTombstone == -1 ? index : firstTombstone;
}
/* 検索操作 */
public String get(int key) {
// key に対応するバケットインデックスを探す
int index = findBucket(key);
// キーと値の組が見つかったら、対応する val を返す
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
return buckets[index].val;
}
// キーと値の組が存在しなければ null を返す
return null;
}
/* 追加操作 */
public void put(int key, String val) {
// 負荷率がしきい値を超えたら、リサイズを実行
if (loadFactor() > loadThres) {
extend();
}
// key に対応するバケットインデックスを探す
int index = findBucket(key);
// キーと値の組が見つかったら、val を上書きして返す
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
buckets[index].val = val;
return;
}
// キーと値の組が存在しない場合は、その組を追加する
buckets[index] = new Pair(key, val);
size++;
}
/* 削除操作 */
public void remove(int key) {
// key に対応するバケットインデックスを探す
int index = findBucket(key);
// キーと値の組が見つかったら、削除マーカーで上書きする
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
buckets[index] = TOMBSTONE;
size--;
}
}
/* ハッシュテーブルを拡張 */
private void extend() {
// 元のハッシュテーブルを一時保存
Pair[] bucketsTmp = buckets;
// リサイズ後の新しいハッシュテーブルを初期化
capacity *= extendRatio;
buckets = new Pair[capacity];
size = 0;
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for (Pair pair : bucketsTmp) {
if (pair != null && pair != TOMBSTONE) {
put(pair.key, pair.val);
}
}
}
/* ハッシュテーブルを出力 */
public void print() {
for (Pair pair : buckets) {
if (pair == null) {
System.out.println("null");
} else if (pair == TOMBSTONE) {
System.out.println("TOMBSTONE");
} else {
System.out.println(pair.key + " -> " + pair.val);
}
}
}
}
/* オープンアドレス法ハッシュテーブル */
class HashMapOpenAddressing {
int size; // キーと値のペア数
int capacity = 4; // ハッシュテーブル容量
double loadThres = 2.0 / 3.0; // リサイズを発動する負荷率のしきい値
int extendRatio = 2; // 拡張倍率
Pair[] buckets; // バケット配列
Pair TOMBSTONE = new(-1, "-1"); // 削除済みマーク
/* コンストラクタ */
public HashMapOpenAddressing() {
size = 0;
buckets = new Pair[capacity];
}
/* ハッシュ関数 */
int HashFunc(int key) {
return key % capacity;
}
/* 負荷率 */
double LoadFactor() {
return (double)size / capacity;
}
/* key に対応するバケットインデックスを探す */
int FindBucket(int key) {
int index = HashFunc(key);
int firstTombstone = -1;
// 線形プロービングを行い、空バケットに達したら終了
while (buckets[index] != null) {
// key が見つかったら、対応するバケットのインデックスを返す
if (buckets[index].key == key) {
// 以前に削除マークが見つかっていれば、そのインデックスへキーと値のペアを移動
if (firstTombstone != -1) {
buckets[firstTombstone] = buckets[index];
buckets[index] = TOMBSTONE;
return firstTombstone; // 移動後のバケットインデックスを返す
}
return index; // バケットのインデックスを返す
}
// 最初に見つかった削除マークを記録
if (firstTombstone == -1 && buckets[index] == TOMBSTONE) {
firstTombstone = index;
}
// バケットのインデックスを計算し、末尾を越えたら先頭に戻る
index = (index + 1) % capacity;
}
// key が存在しない場合は追加位置のインデックスを返す
return firstTombstone == -1 ? index : firstTombstone;
}
/* 検索操作 */
public string? Get(int key) {
// key に対応するバケットインデックスを探す
int index = FindBucket(key);
// キーと値の組が見つかったら、対応する val を返す
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
return buckets[index].val;
}
// キーと値の組が存在しなければ null を返す
return null;
}
/* 追加操作 */
public void Put(int key, string val) {
// 負荷率がしきい値を超えたら、リサイズを実行
if (LoadFactor() > loadThres) {
Extend();
}
// key に対応するバケットインデックスを探す
int index = FindBucket(key);
// キーと値の組が見つかったら、val を上書きして返す
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
buckets[index].val = val;
return;
}
// キーと値の組が存在しない場合は、その組を追加する
buckets[index] = new Pair(key, val);
size++;
}
/* 削除操作 */
public void Remove(int key) {
// key に対応するバケットインデックスを探す
int index = FindBucket(key);
// キーと値の組が見つかったら、削除マーカーで上書きする
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
buckets[index] = TOMBSTONE;
size--;
}
}
/* ハッシュテーブルを拡張 */
void Extend() {
// 元のハッシュテーブルを一時保存
Pair[] bucketsTmp = buckets;
// リサイズ後の新しいハッシュテーブルを初期化
capacity *= extendRatio;
buckets = new Pair[capacity];
size = 0;
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
foreach (Pair pair in bucketsTmp) {
if (pair != null && pair != TOMBSTONE) {
Put(pair.key, pair.val);
}
}
}
/* ハッシュテーブルを出力 */
public void Print() {
foreach (Pair pair in buckets) {
if (pair == null) {
Console.WriteLine("null");
} else if (pair == TOMBSTONE) {
Console.WriteLine("TOMBSTONE");
} else {
Console.WriteLine(pair.key + " -> " + pair.val);
}
}
}
}
/* オープンアドレス法ハッシュテーブル */
type hashMapOpenAddressing struct {
size int // キーと値のペア数
capacity int // ハッシュテーブル容量
loadThres float64 // リサイズを発動する負荷率のしきい値
extendRatio int // 拡張倍率
buckets []*pair // バケット配列
TOMBSTONE *pair // 削除済みマーク
}
/* コンストラクタ */
func newHashMapOpenAddressing() *hashMapOpenAddressing {
return &hashMapOpenAddressing{
size: 0,
capacity: 4,
loadThres: 2.0 / 3.0,
extendRatio: 2,
buckets: make([]*pair, 4),
TOMBSTONE: &pair{-1, "-1"},
}
}
/* ハッシュ関数 */
func (h *hashMapOpenAddressing) hashFunc(key int) int {
return key % h.capacity // キーに基づいてハッシュ値を計算
}
/* 負荷率 */
func (h *hashMapOpenAddressing) loadFactor() float64 {
return float64(h.size) / float64(h.capacity) // 現在の負荷率を計算
}
/* key に対応するバケットインデックスを探す */
func (h *hashMapOpenAddressing) findBucket(key int) int {
index := h.hashFunc(key) // 初期インデックスを取得
firstTombstone := -1 // 最初に遭遇した `TOMBSTONE` の位置を記録する
for h.buckets[index] != nil {
if h.buckets[index].key == key {
if firstTombstone != -1 {
// 以前に削除マークが見つかっていれば、そのインデックスへキーと値のペアを移動
h.buckets[firstTombstone] = h.buckets[index]
h.buckets[index] = h.TOMBSTONE
return firstTombstone // 移動後のバケットインデックスを返す
}
return index // 見つかったインデックスを返す
}
if firstTombstone == -1 && h.buckets[index] == h.TOMBSTONE {
firstTombstone = index // 最初に遭遇した削除マークの位置を記録する
}
index = (index + 1) % h.capacity // 線形探索を行い、末尾を越えたら先頭に戻る
}
// key が存在しない場合は追加位置のインデックスを返す
if firstTombstone != -1 {
return firstTombstone
}
return index
}
/* 検索操作 */
func (h *hashMapOpenAddressing) get(key int) string {
index := h.findBucket(key) // key に対応するバケットインデックスを探す
if h.buckets[index] != nil && h.buckets[index] != h.TOMBSTONE {
return h.buckets[index].val // キーと値の組が見つかったら、対応する val を返す
}
return "" // キーと値のペアが存在しない場合は `""` を返す
}
/* 追加操作 */
func (h *hashMapOpenAddressing) put(key int, val string) {
if h.loadFactor() > h.loadThres {
h.extend() // 負荷率がしきい値を超えたら、リサイズを実行
}
index := h.findBucket(key) // key に対応するバケットインデックスを探す
if h.buckets[index] == nil || h.buckets[index] == h.TOMBSTONE {
h.buckets[index] = &pair{key, val} // キーと値の組が存在しない場合は、その組を追加する
h.size++
} else {
h.buckets[index].val = val // キーと値のペアが見つかった場合は、`val` を上書きする
}
}
/* 削除操作 */
func (h *hashMapOpenAddressing) remove(key int) {
index := h.findBucket(key) // key に対応するバケットインデックスを探す
if h.buckets[index] != nil && h.buckets[index] != h.TOMBSTONE {
h.buckets[index] = h.TOMBSTONE // キーと値の組が見つかったら、削除マーカーで上書きする
h.size--
}
}
/* ハッシュテーブルを拡張 */
func (h *hashMapOpenAddressing) extend() {
oldBuckets := h.buckets // 元のハッシュテーブルを一時保存
h.capacity *= h.extendRatio // 容量を更新
h.buckets = make([]*pair, h.capacity) // リサイズ後の新しいハッシュテーブルを初期化
h.size = 0 // サイズをリセットする
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for _, pair := range oldBuckets {
if pair != nil && pair != h.TOMBSTONE {
h.put(pair.key, pair.val)
}
}
}
/* ハッシュテーブルを出力 */
func (h *hashMapOpenAddressing) print() {
for _, pair := range h.buckets {
if pair == nil {
fmt.Println("nil")
} else if pair == h.TOMBSTONE {
fmt.Println("TOMBSTONE")
} else {
fmt.Printf("%d -> %s\n", pair.key, pair.val)
}
}
}
/* オープンアドレス法ハッシュテーブル */
class HashMapOpenAddressing {
var size: Int // キーと値のペア数
var capacity: Int // ハッシュテーブル容量
var loadThres: Double // リサイズを発動する負荷率のしきい値
var extendRatio: Int // 拡張倍率
var buckets: [Pair?] // バケット配列
var TOMBSTONE: Pair // 削除済みマーク
/* コンストラクタ */
init() {
size = 0
capacity = 4
loadThres = 2.0 / 3.0
extendRatio = 2
buckets = Array(repeating: nil, count: capacity)
TOMBSTONE = Pair(key: -1, val: "-1")
}
/* ハッシュ関数 */
func hashFunc(key: Int) -> Int {
key % capacity
}
/* 負荷率 */
func loadFactor() -> Double {
Double(size) / Double(capacity)
}
/* key に対応するバケットインデックスを探す */
func findBucket(key: Int) -> Int {
var index = hashFunc(key: key)
var firstTombstone = -1
// 線形プロービングを行い、空バケットに達したら終了
while buckets[index] != nil {
// key が見つかったら、対応するバケットのインデックスを返す
if buckets[index]!.key == key {
// 以前に削除マークが見つかっていれば、そのインデックスへキーと値のペアを移動
if firstTombstone != -1 {
buckets[firstTombstone] = buckets[index]
buckets[index] = TOMBSTONE
return firstTombstone // 移動後のバケットインデックスを返す
}
return index // バケットのインデックスを返す
}
// 最初に見つかった削除マークを記録
if firstTombstone == -1 && buckets[index] == TOMBSTONE {
firstTombstone = index
}
// バケットのインデックスを計算し、末尾を越えたら先頭に戻る
index = (index + 1) % capacity
}
// key が存在しない場合は追加位置のインデックスを返す
return firstTombstone == -1 ? index : firstTombstone
}
/* 検索操作 */
func get(key: Int) -> String? {
// key に対応するバケットインデックスを探す
let index = findBucket(key: key)
// キーと値の組が見つかったら、対応する val を返す
if buckets[index] != nil, buckets[index] != TOMBSTONE {
return buckets[index]!.val
}
// キーと値の組が存在しなければ null を返す
return nil
}
/* 追加操作 */
func put(key: Int, val: String) {
// 負荷率がしきい値を超えたら、リサイズを実行
if loadFactor() > loadThres {
extend()
}
// key に対応するバケットインデックスを探す
let index = findBucket(key: key)
// キーと値の組が見つかったら、val を上書きして返す
if buckets[index] != nil, buckets[index] != TOMBSTONE {
buckets[index]!.val = val
return
}
// キーと値の組が存在しない場合は、その組を追加する
buckets[index] = Pair(key: key, val: val)
size += 1
}
/* 削除操作 */
func remove(key: Int) {
// key に対応するバケットインデックスを探す
let index = findBucket(key: key)
// キーと値の組が見つかったら、削除マーカーで上書きする
if buckets[index] != nil, buckets[index] != TOMBSTONE {
buckets[index] = TOMBSTONE
size -= 1
}
}
/* ハッシュテーブルを拡張 */
func extend() {
// 元のハッシュテーブルを一時保存
let bucketsTmp = buckets
// リサイズ後の新しいハッシュテーブルを初期化
capacity *= extendRatio
buckets = Array(repeating: nil, count: capacity)
size = 0
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for pair in bucketsTmp {
if let pair, pair != TOMBSTONE {
put(key: pair.key, val: pair.val)
}
}
}
/* ハッシュテーブルを出力 */
func print() {
for pair in buckets {
if pair == nil {
Swift.print("null")
} else if pair == TOMBSTONE {
Swift.print("TOMBSTONE")
} else {
Swift.print("\(pair!.key) -> \(pair!.val)")
}
}
}
}
/* オープンアドレス法ハッシュテーブル */
class HashMapOpenAddressing {
#size; // キーと値のペア数
#capacity; // ハッシュテーブル容量
#loadThres; // リサイズを発動する負荷率のしきい値
#extendRatio; // 拡張倍率
#buckets; // バケット配列
#TOMBSTONE; // 削除済みマーク
/* コンストラクタ */
constructor() {
this.#size = 0; // キーと値のペア数
this.#capacity = 4; // ハッシュテーブル容量
this.#loadThres = 2.0 / 3.0; // リサイズを発動する負荷率のしきい値
this.#extendRatio = 2; // 拡張倍率
this.#buckets = Array(this.#capacity).fill(null); // バケット配列
this.#TOMBSTONE = new Pair(-1, '-1'); // 削除済みマーク
}
/* ハッシュ関数 */
#hashFunc(key) {
return key % this.#capacity;
}
/* 負荷率 */
#loadFactor() {
return this.#size / this.#capacity;
}
/* key に対応するバケットインデックスを探す */
#findBucket(key) {
let index = this.#hashFunc(key);
let firstTombstone = -1;
// 線形プロービングを行い、空バケットに達したら終了
while (this.#buckets[index] !== null) {
// key が見つかったら、対応するバケットのインデックスを返す
if (this.#buckets[index].key === key) {
// 以前に削除マークが見つかっていれば、そのインデックスへキーと値のペアを移動
if (firstTombstone !== -1) {
this.#buckets[firstTombstone] = this.#buckets[index];
this.#buckets[index] = this.#TOMBSTONE;
return firstTombstone; // 移動後のバケットインデックスを返す
}
return index; // バケットのインデックスを返す
}
// 最初に見つかった削除マークを記録
if (
firstTombstone === -1 &&
this.#buckets[index] === this.#TOMBSTONE
) {
firstTombstone = index;
}
// バケットのインデックスを計算し、末尾を越えたら先頭に戻る
index = (index + 1) % this.#capacity;
}
// key が存在しない場合は追加位置のインデックスを返す
return firstTombstone === -1 ? index : firstTombstone;
}
/* 検索操作 */
get(key) {
// key に対応するバケットインデックスを探す
const index = this.#findBucket(key);
// キーと値の組が見つかったら、対応する val を返す
if (
this.#buckets[index] !== null &&
this.#buckets[index] !== this.#TOMBSTONE
) {
return this.#buckets[index].val;
}
// キーと値の組が存在しなければ null を返す
return null;
}
/* 追加操作 */
put(key, val) {
// 負荷率がしきい値を超えたら、リサイズを実行
if (this.#loadFactor() > this.#loadThres) {
this.#extend();
}
// key に対応するバケットインデックスを探す
const index = this.#findBucket(key);
// キーと値の組が見つかったら、val を上書きして返す
if (
this.#buckets[index] !== null &&
this.#buckets[index] !== this.#TOMBSTONE
) {
this.#buckets[index].val = val;
return;
}
// キーと値の組が存在しない場合は、その組を追加する
this.#buckets[index] = new Pair(key, val);
this.#size++;
}
/* 削除操作 */
remove(key) {
// key に対応するバケットインデックスを探す
const index = this.#findBucket(key);
// キーと値の組が見つかったら、削除マーカーで上書きする
if (
this.#buckets[index] !== null &&
this.#buckets[index] !== this.#TOMBSTONE
) {
this.#buckets[index] = this.#TOMBSTONE;
this.#size--;
}
}
/* ハッシュテーブルを拡張 */
#extend() {
// 元のハッシュテーブルを一時保存
const bucketsTmp = this.#buckets;
// リサイズ後の新しいハッシュテーブルを初期化
this.#capacity *= this.#extendRatio;
this.#buckets = Array(this.#capacity).fill(null);
this.#size = 0;
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for (const pair of bucketsTmp) {
if (pair !== null && pair !== this.#TOMBSTONE) {
this.put(pair.key, pair.val);
}
}
}
/* ハッシュテーブルを出力 */
print() {
for (const pair of this.#buckets) {
if (pair === null) {
console.log('null');
} else if (pair === this.#TOMBSTONE) {
console.log('TOMBSTONE');
} else {
console.log(pair.key + ' -> ' + pair.val);
}
}
}
}
/* オープンアドレス法ハッシュテーブル */
class HashMapOpenAddressing {
private size: number; // キーと値のペア数
private capacity: number; // ハッシュテーブル容量
private loadThres: number; // リサイズを発動する負荷率のしきい値
private extendRatio: number; // 拡張倍率
private buckets: Array<Pair | null>; // バケット配列
private TOMBSTONE: Pair; // 削除済みマーク
/* コンストラクタ */
constructor() {
this.size = 0; // キーと値のペア数
this.capacity = 4; // ハッシュテーブル容量
this.loadThres = 2.0 / 3.0; // リサイズを発動する負荷率のしきい値
this.extendRatio = 2; // 拡張倍率
this.buckets = Array(this.capacity).fill(null); // バケット配列
this.TOMBSTONE = new Pair(-1, '-1'); // 削除済みマーク
}
/* ハッシュ関数 */
private hashFunc(key: number): number {
return key % this.capacity;
}
/* 負荷率 */
private loadFactor(): number {
return this.size / this.capacity;
}
/* key に対応するバケットインデックスを探す */
private findBucket(key: number): number {
let index = this.hashFunc(key);
let firstTombstone = -1;
// 線形プロービングを行い、空バケットに達したら終了
while (this.buckets[index] !== null) {
// key が見つかったら、対応するバケットのインデックスを返す
if (this.buckets[index]!.key === key) {
// 以前に削除マークが見つかっていれば、そのインデックスへキーと値のペアを移動
if (firstTombstone !== -1) {
this.buckets[firstTombstone] = this.buckets[index];
this.buckets[index] = this.TOMBSTONE;
return firstTombstone; // 移動後のバケットインデックスを返す
}
return index; // バケットのインデックスを返す
}
// 最初に見つかった削除マークを記録
if (
firstTombstone === -1 &&
this.buckets[index] === this.TOMBSTONE
) {
firstTombstone = index;
}
// バケットのインデックスを計算し、末尾を越えたら先頭に戻る
index = (index + 1) % this.capacity;
}
// key が存在しない場合は追加位置のインデックスを返す
return firstTombstone === -1 ? index : firstTombstone;
}
/* 検索操作 */
get(key: number): string | null {
// key に対応するバケットインデックスを探す
const index = this.findBucket(key);
// キーと値の組が見つかったら、対応する val を返す
if (
this.buckets[index] !== null &&
this.buckets[index] !== this.TOMBSTONE
) {
return this.buckets[index]!.val;
}
// キーと値の組が存在しなければ null を返す
return null;
}
/* 追加操作 */
put(key: number, val: string): void {
// 負荷率がしきい値を超えたら、リサイズを実行
if (this.loadFactor() > this.loadThres) {
this.extend();
}
// key に対応するバケットインデックスを探す
const index = this.findBucket(key);
// キーと値の組が見つかったら、val を上書きして返す
if (
this.buckets[index] !== null &&
this.buckets[index] !== this.TOMBSTONE
) {
this.buckets[index]!.val = val;
return;
}
// キーと値の組が存在しない場合は、その組を追加する
this.buckets[index] = new Pair(key, val);
this.size++;
}
/* 削除操作 */
remove(key: number): void {
// key に対応するバケットインデックスを探す
const index = this.findBucket(key);
// キーと値の組が見つかったら、削除マーカーで上書きする
if (
this.buckets[index] !== null &&
this.buckets[index] !== this.TOMBSTONE
) {
this.buckets[index] = this.TOMBSTONE;
this.size--;
}
}
/* ハッシュテーブルを拡張 */
private extend(): void {
// 元のハッシュテーブルを一時保存
const bucketsTmp = this.buckets;
// リサイズ後の新しいハッシュテーブルを初期化
this.capacity *= this.extendRatio;
this.buckets = Array(this.capacity).fill(null);
this.size = 0;
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for (const pair of bucketsTmp) {
if (pair !== null && pair !== this.TOMBSTONE) {
this.put(pair.key, pair.val);
}
}
}
/* ハッシュテーブルを出力 */
print(): void {
for (const pair of this.buckets) {
if (pair === null) {
console.log('null');
} else if (pair === this.TOMBSTONE) {
console.log('TOMBSTONE');
} else {
console.log(pair.key + ' -> ' + pair.val);
}
}
}
}
/* オープンアドレス法ハッシュテーブル */
class HashMapOpenAddressing {
late int _size; // キーと値のペア数
int _capacity = 4; // ハッシュテーブル容量
double _loadThres = 2.0 / 3.0; // リサイズを発動する負荷率のしきい値
int _extendRatio = 2; // 拡張倍率
late List<Pair?> _buckets; // バケット配列
Pair _TOMBSTONE = Pair(-1, "-1"); // 削除済みマーク
/* コンストラクタ */
HashMapOpenAddressing() {
_size = 0;
_buckets = List.generate(_capacity, (index) => null);
}
/* ハッシュ関数 */
int hashFunc(int key) {
return key % _capacity;
}
/* 負荷率 */
double loadFactor() {
return _size / _capacity;
}
/* key に対応するバケットインデックスを探す */
int findBucket(int key) {
int index = hashFunc(key);
int firstTombstone = -1;
// 線形プロービングを行い、空バケットに達したら終了
while (_buckets[index] != null) {
// key が見つかったら、対応するバケットのインデックスを返す
if (_buckets[index]!.key == key) {
// 以前に削除マークが見つかっていれば、そのインデックスへキーと値のペアを移動
if (firstTombstone != -1) {
_buckets[firstTombstone] = _buckets[index];
_buckets[index] = _TOMBSTONE;
return firstTombstone; // 移動後のバケットインデックスを返す
}
return index; // バケットのインデックスを返す
}
// 最初に見つかった削除マークを記録
if (firstTombstone == -1 && _buckets[index] == _TOMBSTONE) {
firstTombstone = index;
}
// バケットのインデックスを計算し、末尾を越えたら先頭に戻る
index = (index + 1) % _capacity;
}
// key が存在しない場合は追加位置のインデックスを返す
return firstTombstone == -1 ? index : firstTombstone;
}
/* 検索操作 */
String? get(int key) {
// key に対応するバケットインデックスを探す
int index = findBucket(key);
// キーと値の組が見つかったら、対応する val を返す
if (_buckets[index] != null && _buckets[index] != _TOMBSTONE) {
return _buckets[index]!.val;
}
// キーと値の組が存在しなければ null を返す
return null;
}
/* 追加操作 */
void put(int key, String val) {
// 負荷率がしきい値を超えたら、リサイズを実行
if (loadFactor() > _loadThres) {
extend();
}
// key に対応するバケットインデックスを探す
int index = findBucket(key);
// キーと値の組が見つかったら、val を上書きして返す
if (_buckets[index] != null && _buckets[index] != _TOMBSTONE) {
_buckets[index]!.val = val;
return;
}
// キーと値の組が存在しない場合は、その組を追加する
_buckets[index] = new Pair(key, val);
_size++;
}
/* 削除操作 */
void remove(int key) {
// key に対応するバケットインデックスを探す
int index = findBucket(key);
// キーと値の組が見つかったら、削除マーカーで上書きする
if (_buckets[index] != null && _buckets[index] != _TOMBSTONE) {
_buckets[index] = _TOMBSTONE;
_size--;
}
}
/* ハッシュテーブルを拡張 */
void extend() {
// 元のハッシュテーブルを一時保存
List<Pair?> bucketsTmp = _buckets;
// リサイズ後の新しいハッシュテーブルを初期化
_capacity *= _extendRatio;
_buckets = List.generate(_capacity, (index) => null);
_size = 0;
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for (Pair? pair in bucketsTmp) {
if (pair != null && pair != _TOMBSTONE) {
put(pair.key, pair.val);
}
}
}
/* ハッシュテーブルを出力 */
void printHashMap() {
for (Pair? pair in _buckets) {
if (pair == null) {
print("null");
} else if (pair == _TOMBSTONE) {
print("TOMBSTONE");
} else {
print("${pair.key} -> ${pair.val}");
}
}
}
}
/* オープンアドレス法ハッシュテーブル */
struct HashMapOpenAddressing {
size: usize, // キーと値のペア数
capacity: usize, // ハッシュテーブル容量
load_thres: f64, // リサイズを発動する負荷率のしきい値
extend_ratio: usize, // 拡張倍率
buckets: Vec<Option<Pair>>, // バケット配列
TOMBSTONE: Option<Pair>, // 削除済みマーク
}
impl HashMapOpenAddressing {
/* コンストラクタ */
fn new() -> Self {
Self {
size: 0,
capacity: 4,
load_thres: 2.0 / 3.0,
extend_ratio: 2,
buckets: vec![None; 4],
TOMBSTONE: Some(Pair {
key: -1,
val: "-1".to_string(),
}),
}
}
/* ハッシュ関数 */
fn hash_func(&self, key: i32) -> usize {
(key % self.capacity as i32) as usize
}
/* 負荷率 */
fn load_factor(&self) -> f64 {
self.size as f64 / self.capacity as f64
}
/* key に対応するバケットインデックスを探す */
fn find_bucket(&mut self, key: i32) -> usize {
let mut index = self.hash_func(key);
let mut first_tombstone = -1;
// 線形プロービングを行い、空バケットに達したら終了
while self.buckets[index].is_some() {
// `key` に遭遇したら、対応するバケットのインデックスを返す
if self.buckets[index].as_ref().unwrap().key == key {
// 以前に削除マークに遭遇していた場合は、キーと値のペアをそのインデックスへ移動する
if first_tombstone != -1 {
self.buckets[first_tombstone as usize] = self.buckets[index].take();
self.buckets[index] = self.TOMBSTONE.clone();
return first_tombstone as usize; // 移動後のバケットインデックスを返す
}
return index; // バケットのインデックスを返す
}
// 最初に見つかった削除マークを記録
if first_tombstone == -1 && self.buckets[index] == self.TOMBSTONE {
first_tombstone = index as i32;
}
// バケットのインデックスを計算し、末尾を越えたら先頭に戻る
index = (index + 1) % self.capacity;
}
// key が存在しない場合は追加位置のインデックスを返す
if first_tombstone == -1 {
index
} else {
first_tombstone as usize
}
}
/* 検索操作 */
fn get(&mut self, key: i32) -> Option<&str> {
// key に対応するバケットインデックスを探す
let index = self.find_bucket(key);
// キーと値の組が見つかったら、対応する val を返す
if self.buckets[index].is_some() && self.buckets[index] != self.TOMBSTONE {
return self.buckets[index].as_ref().map(|pair| &pair.val as &str);
}
// キーと値の組が存在しなければ null を返す
None
}
/* 追加操作 */
fn put(&mut self, key: i32, val: String) {
// 負荷率がしきい値を超えたら、リサイズを実行
if self.load_factor() > self.load_thres {
self.extend();
}
// key に対応するバケットインデックスを探す
let index = self.find_bucket(key);
// キーと値の組が見つかったら、val を上書きして返す
if self.buckets[index].is_some() && self.buckets[index] != self.TOMBSTONE {
self.buckets[index].as_mut().unwrap().val = val;
return;
}
// キーと値の組が存在しない場合は、その組を追加する
self.buckets[index] = Some(Pair { key, val });
self.size += 1;
}
/* 削除操作 */
fn remove(&mut self, key: i32) {
// key に対応するバケットインデックスを探す
let index = self.find_bucket(key);
// キーと値の組が見つかったら、削除マーカーで上書きする
if self.buckets[index].is_some() && self.buckets[index] != self.TOMBSTONE {
self.buckets[index] = self.TOMBSTONE.clone();
self.size -= 1;
}
}
/* ハッシュテーブルを拡張 */
fn extend(&mut self) {
// 元のハッシュテーブルを一時保存
let buckets_tmp = self.buckets.clone();
// リサイズ後の新しいハッシュテーブルを初期化
self.capacity *= self.extend_ratio;
self.buckets = vec![None; self.capacity];
self.size = 0;
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for pair in buckets_tmp {
if pair.is_none() || pair == self.TOMBSTONE {
continue;
}
let pair = pair.unwrap();
self.put(pair.key, pair.val);
}
}
/* ハッシュテーブルを出力 */
fn print(&self) {
for pair in &self.buckets {
if pair.is_none() {
println!("null");
} else if pair == &self.TOMBSTONE {
println!("TOMBSTONE");
} else {
let pair = pair.as_ref().unwrap();
println!("{} -> {}", pair.key, pair.val);
}
}
}
}
/* オープンアドレス法ハッシュテーブル */
typedef struct {
int size; // キーと値のペア数
int capacity; // ハッシュテーブル容量
double loadThres; // リサイズを発動する負荷率のしきい値
int extendRatio; // 拡張倍率
Pair **buckets; // バケット配列
Pair *TOMBSTONE; // 削除済みマーク
} HashMapOpenAddressing;
/* コンストラクタ */
HashMapOpenAddressing *newHashMapOpenAddressing() {
HashMapOpenAddressing *hashMap = (HashMapOpenAddressing *)malloc(sizeof(HashMapOpenAddressing));
hashMap->size = 0;
hashMap->capacity = 4;
hashMap->loadThres = 2.0 / 3.0;
hashMap->extendRatio = 2;
hashMap->buckets = (Pair **)calloc(hashMap->capacity, sizeof(Pair *));
hashMap->TOMBSTONE = (Pair *)malloc(sizeof(Pair));
hashMap->TOMBSTONE->key = -1;
hashMap->TOMBSTONE->val = "-1";
return hashMap;
}
/* デストラクタ */
void delHashMapOpenAddressing(HashMapOpenAddressing *hashMap) {
for (int i = 0; i < hashMap->capacity; i++) {
Pair *pair = hashMap->buckets[i];
if (pair != NULL && pair != hashMap->TOMBSTONE) {
free(pair->val);
free(pair);
}
}
free(hashMap->buckets);
free(hashMap->TOMBSTONE);
free(hashMap);
}
/* ハッシュ関数 */
int hashFunc(HashMapOpenAddressing *hashMap, int key) {
return key % hashMap->capacity;
}
/* 負荷率 */
double loadFactor(HashMapOpenAddressing *hashMap) {
return (double)hashMap->size / (double)hashMap->capacity;
}
/* key に対応するバケットインデックスを探す */
int findBucket(HashMapOpenAddressing *hashMap, int key) {
int index = hashFunc(hashMap, key);
int firstTombstone = -1;
// 線形プロービングを行い、空バケットに達したら終了
while (hashMap->buckets[index] != NULL) {
// key が見つかったら、対応するバケットのインデックスを返す
if (hashMap->buckets[index]->key == key) {
// 以前に削除マークが見つかっていれば、そのインデックスへキーと値のペアを移動
if (firstTombstone != -1) {
hashMap->buckets[firstTombstone] = hashMap->buckets[index];
hashMap->buckets[index] = hashMap->TOMBSTONE;
return firstTombstone; // 移動後のバケットインデックスを返す
}
return index; // バケットのインデックスを返す
}
// 最初に見つかった削除マークを記録
if (firstTombstone == -1 && hashMap->buckets[index] == hashMap->TOMBSTONE) {
firstTombstone = index;
}
// バケットのインデックスを計算し、末尾を越えたら先頭に戻る
index = (index + 1) % hashMap->capacity;
}
// key が存在しない場合は追加位置のインデックスを返す
return firstTombstone == -1 ? index : firstTombstone;
}
/* 検索操作 */
char *get(HashMapOpenAddressing *hashMap, int key) {
// key に対応するバケットインデックスを探す
int index = findBucket(hashMap, key);
// キーと値の組が見つかったら、対応する val を返す
if (hashMap->buckets[index] != NULL && hashMap->buckets[index] != hashMap->TOMBSTONE) {
return hashMap->buckets[index]->val;
}
// キーと値の組が存在しない場合は空文字列を返す
return "";
}
/* 追加操作 */
void put(HashMapOpenAddressing *hashMap, int key, char *val) {
// 負荷率がしきい値を超えたら、リサイズを実行
if (loadFactor(hashMap) > hashMap->loadThres) {
extend(hashMap);
}
// key に対応するバケットインデックスを探す
int index = findBucket(hashMap, key);
// キーと値の組が見つかったら、val を上書きして返す
if (hashMap->buckets[index] != NULL && hashMap->buckets[index] != hashMap->TOMBSTONE) {
free(hashMap->buckets[index]->val);
hashMap->buckets[index]->val = (char *)malloc(sizeof(strlen(val) + 1));
strcpy(hashMap->buckets[index]->val, val);
hashMap->buckets[index]->val[strlen(val)] = '\0';
return;
}
// キーと値の組が存在しない場合は、その組を追加する
Pair *pair = (Pair *)malloc(sizeof(Pair));
pair->key = key;
pair->val = (char *)malloc(sizeof(strlen(val) + 1));
strcpy(pair->val, val);
pair->val[strlen(val)] = '\0';
hashMap->buckets[index] = pair;
hashMap->size++;
}
/* 削除操作 */
void removeItem(HashMapOpenAddressing *hashMap, int key) {
// key に対応するバケットインデックスを探す
int index = findBucket(hashMap, key);
// キーと値の組が見つかったら、削除マーカーで上書きする
if (hashMap->buckets[index] != NULL && hashMap->buckets[index] != hashMap->TOMBSTONE) {
Pair *pair = hashMap->buckets[index];
free(pair->val);
free(pair);
hashMap->buckets[index] = hashMap->TOMBSTONE;
hashMap->size--;
}
}
/* ハッシュテーブルを拡張 */
void extend(HashMapOpenAddressing *hashMap) {
// 元のハッシュテーブルを一時保存
Pair **bucketsTmp = hashMap->buckets;
int oldCapacity = hashMap->capacity;
// リサイズ後の新しいハッシュテーブルを初期化
hashMap->capacity *= hashMap->extendRatio;
hashMap->buckets = (Pair **)calloc(hashMap->capacity, sizeof(Pair *));
hashMap->size = 0;
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for (int i = 0; i < oldCapacity; i++) {
Pair *pair = bucketsTmp[i];
if (pair != NULL && pair != hashMap->TOMBSTONE) {
put(hashMap, pair->key, pair->val);
free(pair->val);
free(pair);
}
}
free(bucketsTmp);
}
/* ハッシュテーブルを出力 */
void print(HashMapOpenAddressing *hashMap) {
for (int i = 0; i < hashMap->capacity; i++) {
Pair *pair = hashMap->buckets[i];
if (pair == NULL) {
printf("NULL\n");
} else if (pair == hashMap->TOMBSTONE) {
printf("TOMBSTONE\n");
} else {
printf("%d -> %s\n", pair->key, pair->val);
}
}
}
/* オープンアドレス法ハッシュテーブル */
class HashMapOpenAddressing {
private var size: Int // キーと値のペア数
private var capacity: Int // ハッシュテーブル容量
private val loadThres: Double // リサイズを発動する負荷率のしきい値
private val extendRatio: Int // 拡張倍率
private var buckets: Array<Pair?> // バケット配列
private val TOMBSTONE: Pair // 削除済みマーク
/* コンストラクタ */
init {
size = 0
capacity = 4
loadThres = 2.0 / 3.0
extendRatio = 2
buckets = arrayOfNulls(capacity)
TOMBSTONE = Pair(-1, "-1")
}
/* ハッシュ関数 */
fun hashFunc(key: Int): Int {
return key % capacity
}
/* 負荷率 */
fun loadFactor(): Double {
return (size / capacity).toDouble()
}
/* key に対応するバケットインデックスを探す */
fun findBucket(key: Int): Int {
var index = hashFunc(key)
var firstTombstone = -1
// 線形プロービングを行い、空バケットに達したら終了
while (buckets[index] != null) {
// key が見つかったら、対応するバケットのインデックスを返す
if (buckets[index]?.key == key) {
// 以前に削除マークが見つかっていれば、そのインデックスへキーと値のペアを移動
if (firstTombstone != -1) {
buckets[firstTombstone] = buckets[index]
buckets[index] = TOMBSTONE
return firstTombstone // 移動後のバケットインデックスを返す
}
return index // バケットのインデックスを返す
}
// 最初に見つかった削除マークを記録
if (firstTombstone == -1 && buckets[index] == TOMBSTONE) {
firstTombstone = index
}
// バケットのインデックスを計算し、末尾を越えたら先頭に戻る
index = (index + 1) % capacity
}
// key が存在しない場合は追加位置のインデックスを返す
return if (firstTombstone == -1) index else firstTombstone
}
/* 検索操作 */
fun get(key: Int): String? {
// key に対応するバケットインデックスを探す
val index = findBucket(key)
// キーと値の組が見つかったら、対応する val を返す
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
return buckets[index]?._val
}
// キーと値の組が存在しなければ null を返す
return null
}
/* 追加操作 */
fun put(key: Int, _val: String) {
// 負荷率がしきい値を超えたら、リサイズを実行
if (loadFactor() > loadThres) {
extend()
}
// key に対応するバケットインデックスを探す
val index = findBucket(key)
// キーと値の組が見つかったら、val を上書きして返す
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
buckets[index]!!._val = _val
return
}
// キーと値の組が存在しない場合は、その組を追加する
buckets[index] = Pair(key, _val)
size++
}
/* 削除操作 */
fun remove(key: Int) {
// key に対応するバケットインデックスを探す
val index = findBucket(key)
// キーと値の組が見つかったら、削除マーカーで上書きする
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
buckets[index] = TOMBSTONE
size--
}
}
/* ハッシュテーブルを拡張 */
fun extend() {
// 元のハッシュテーブルを一時保存
val bucketsTmp = buckets
// リサイズ後の新しいハッシュテーブルを初期化
capacity *= extendRatio
buckets = arrayOfNulls(capacity)
size = 0
// キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for (pair in bucketsTmp) {
if (pair != null && pair != TOMBSTONE) {
put(pair.key, pair._val)
}
}
}
/* ハッシュテーブルを出力 */
fun print() {
for (pair in buckets) {
if (pair == null) {
println("null")
} else if (pair == TOMBSTONE) {
println("TOMESTOME")
} else {
println("${pair.key} -> ${pair._val}")
}
}
}
}
### オープンアドレス法ハッシュテーブル ###
class HashMapOpenAddressing
TOMBSTONE = Pair.new(-1, '-1') # 削除済みマーク
### コンストラクタ ###
def initialize
@size = 0 # キーと値のペア数
@capacity = 4 # ハッシュテーブル容量
@load_thres = 2.0 / 3.0 # リサイズを発動する負荷率のしきい値
@extend_ratio = 2 # 拡張倍率
@buckets = Array.new(@capacity) # バケット配列
end
### ハッシュ関数 ###
def hash_func(key)
key % @capacity
end
### 負荷率 ###
def load_factor
@size / @capacity
end
### key に対応するバケットインデックスを検索 ###
def find_bucket(key)
index = hash_func(key)
first_tombstone = -1
# 線形プロービングを行い、空バケットに達したら終了
while !@buckets[index].nil?
# key が見つかったら、対応するバケットのインデックスを返す
if @buckets[index].key == key
# 以前に削除マークが見つかっていれば、そのインデックスへキーと値のペアを移動
if first_tombstone != -1
@buckets[first_tombstone] = @buckets[index]
@buckets[index] = TOMBSTONE
return first_tombstone # 移動後のバケットインデックスを返す
end
return index # バケットのインデックスを返す
end
# 最初に見つかった削除マークを記録
first_tombstone = index if first_tombstone == -1 && @buckets[index] == TOMBSTONE
# バケットのインデックスを計算し、末尾を越えたら先頭に戻る
index = (index + 1) % @capacity
end
# key が存在しない場合は追加位置のインデックスを返す
first_tombstone == -1 ? index : first_tombstone
end
### 検索操作 ###
def get(key)
# key に対応するバケットインデックスを探す
index = find_bucket(key)
# キーと値の組が見つかったら、対応する val を返す
return @buckets[index].val unless [nil, TOMBSTONE].include?(@buckets[index])
# キーと値のペアが存在しない場合は `nil` を返す
nil
end
### 追加操作 ###
def put(key, val)
# 負荷率がしきい値を超えたら、リサイズを実行
extend if load_factor > @load_thres
# key に対応するバケットインデックスを探す
index = find_bucket(key)
# キーと値のペアが見つかった場合は、`val` を上書きして返す
unless [nil, TOMBSTONE].include?(@buckets[index])
@buckets[index].val = val
return
end
# キーと値の組が存在しない場合は、その組を追加する
@buckets[index] = Pair.new(key, val)
@size += 1
end
### 削除操作 ###
def remove(key)
# key に対応するバケットインデックスを探す
index = find_bucket(key)
# キーと値の組が見つかったら、削除マーカーで上書きする
unless [nil, TOMBSTONE].include?(@buckets[index])
@buckets[index] = TOMBSTONE
@size -= 1
end
end
### ハッシュテーブルを拡張 ###
def extend
# 元のハッシュテーブルを一時保存
buckets_tmp = @buckets
# リサイズ後の新しいハッシュテーブルを初期化
@capacity *= @extend_ratio
@buckets = Array.new(@capacity)
@size = 0
# キーと値のペアを元のハッシュテーブルから新しいハッシュテーブルへ移す
for pair in buckets_tmp
put(pair.key, pair.val) unless [nil, TOMBSTONE].include?(pair)
end
end
### ハッシュテーブルを出力 ###
def print
for pair in @buckets
if pair.nil?
puts "Nil"
elsif pair == TOMBSTONE
puts "TOMBSTONE"
else
puts "#{pair.key} -> #{pair.val}"
end
end
end
end
2. 二次探索¶
二次探索は線形探索に似ており、オープンアドレッシングの一般的な戦略の 1 つです。衝突が発生したとき、二次探索では単純に固定歩数を飛ばすのではなく、「探索回数の二乗」に相当する歩数、すなわち \(1, 4, 9, \dots\) 歩を飛ばします。
二次探索には主に次の利点があります。
- 二次探索は、探索回数の二乗の距離を飛ばすことで、線形探索のクラスタリング効果を緩和しようとします。
- 二次探索はより大きな距離を飛ばして空き位置を探すため、データ分布がより均一になるのに役立ちます。
しかし、二次探索は完璧ではありません。
- 依然としてクラスタリング現象は存在し、ある位置が他の位置より占有されやすいことがあります。
- 二乗の増加により、二次探索はハッシュテーブル全体を探索できない可能性があります。これは、ハッシュテーブルに空バケットがあっても、二次探索ではそこに到達できないことがあることを意味します。
3. 多重ハッシュ¶
その名のとおり、多重ハッシュ法では複数のハッシュ関数 \(f_1(x)\)、\(f_2(x)\)、\(f_3(x)\)、\(\dots\) を使って探索を行います。
- 要素の挿入:ハッシュ関数 \(f_1(x)\) で衝突が発生した場合は、\(f_2(x)\) を試し、以下同様に、空き位置が見つかるまで続けてから要素を挿入します。
- 要素の検索:同じハッシュ関数の順序で探索し、対象要素が見つかった時点で返します。空き位置に遭遇するか、すべてのハッシュ関数を試しても見つからない場合は、ハッシュテーブル内にその要素は存在しないため、
Noneを返します。
線形探索と比べると、多重ハッシュ法はクラスタリングを起こしにくい一方で、複数のハッシュ関数により追加の計算量が発生します。
Tip
注意してください。オープンアドレッシング(線形探索、二次探索、多重ハッシュ)のハッシュテーブルには、いずれも「要素を直接削除できない」という問題があります。
6.2.3 プログラミング言語の選択¶
各種プログラミング言語は異なるハッシュテーブル実装戦略を採用しています。以下にいくつか例を挙げます。
- Python はオープンアドレッシングを採用しています。辞書
dictは疑似乱数を用いて探索します。 - Java はチェイン法を採用しています。JDK 1.8 以降、
HashMap内の配列長が 64 に達し、かつ連結リスト長が 8 に達すると、連結リストは検索性能を高めるため赤黒木に変換されます。 - Go はチェイン法を採用しています。Go では各バケットに最大 8 個のキーと値のペアを格納でき、容量を超えるとオーバーフローバケットを連結します。オーバーフローバケットが多すぎる場合は、性能を確保するために特殊な等量拡張操作を実行します。