2.3 時間計算量¶
実行時間はアルゴリズムの効率を直感的かつ正確に反映します。あるコードの実行時間を正確に見積もりたい場合、どのようにすればよいでしょうか?
- 実行プラットフォームを特定する。ハードウェア構成、プログラミング言語、システム環境などが含まれ、これらの要因はいずれもコードの実行効率に影響します。
- 各種計算操作に必要な実行時間を評価する。例えば加算
+には 1 ns 、乗算*には 10 ns 、出力print()には 5 ns などが必要です。 - コード中のすべての計算操作を数える。そして各操作の実行時間を合計することで、実行時間を得ます。
例えば次のコードでは、入力データサイズを \(n\) とします:
上記の方法に基づくと、アルゴリズムの実行時間は \((6n + 12)\) ns になります:
しかし実際には、アルゴリズムの実行時間を統計的に求めることは合理的でも現実的でもありません。まず、見積もり時間を実行プラットフォームに縛りたくありません。アルゴリズムはさまざまな異なるプラットフォームで動作する必要があるからです。次に、各種操作の実行時間を知ること自体が難しく、見積もりの難易度を大きく引き上げます。
2.3.1 実行時間の増加傾向を捉える¶
時間計算量の分析で扱うのはアルゴリズムの実行時間そのものではなく、**データ量が増えたときに実行時間がどう増加するかという傾向**です。
「実行時間の増加傾向」という概念はやや抽象的なので、例を通して理解してみましょう。入力データサイズを \(n\) とし、3 つのアルゴリズム A、B、C を考えます:
// アルゴリズム A の時間計算量:定数階
function algorithm_A(n: number): void {
console.log(0);
}
// アルゴリズム B の時間計算量:線形階
function algorithm_B(n: number): void {
for (let i = 0; i < n; i++) {
console.log(0);
}
}
// アルゴリズム C の時間計算量:定数階
function algorithm_C(n: number): void {
for (let i = 0; i < 1000000; i++) {
console.log(0);
}
}
以下の図は、上記 3 つのアルゴリズム関数の時間計算量を示しています。
- アルゴリズム
Aには出力操作が \(1\) 回しかなく、実行時間は \(n\) が大きくなっても増加しません。このアルゴリズムの時間計算量を「定数階」と呼びます。 - アルゴリズム
Bの出力操作は \(n\) 回ループする必要があり、実行時間は \(n\) の増加に対して線形に増加します。このアルゴリズムの時間計算量は「線形階」と呼ばれます。 - アルゴリズム
Cの出力操作は \(1000000\) 回ループする必要があり、実行時間は長いものの、入力データサイズ \(n\) とは無関係です。したがってCの時間計算量はAと同じく、依然として「定数階」です。
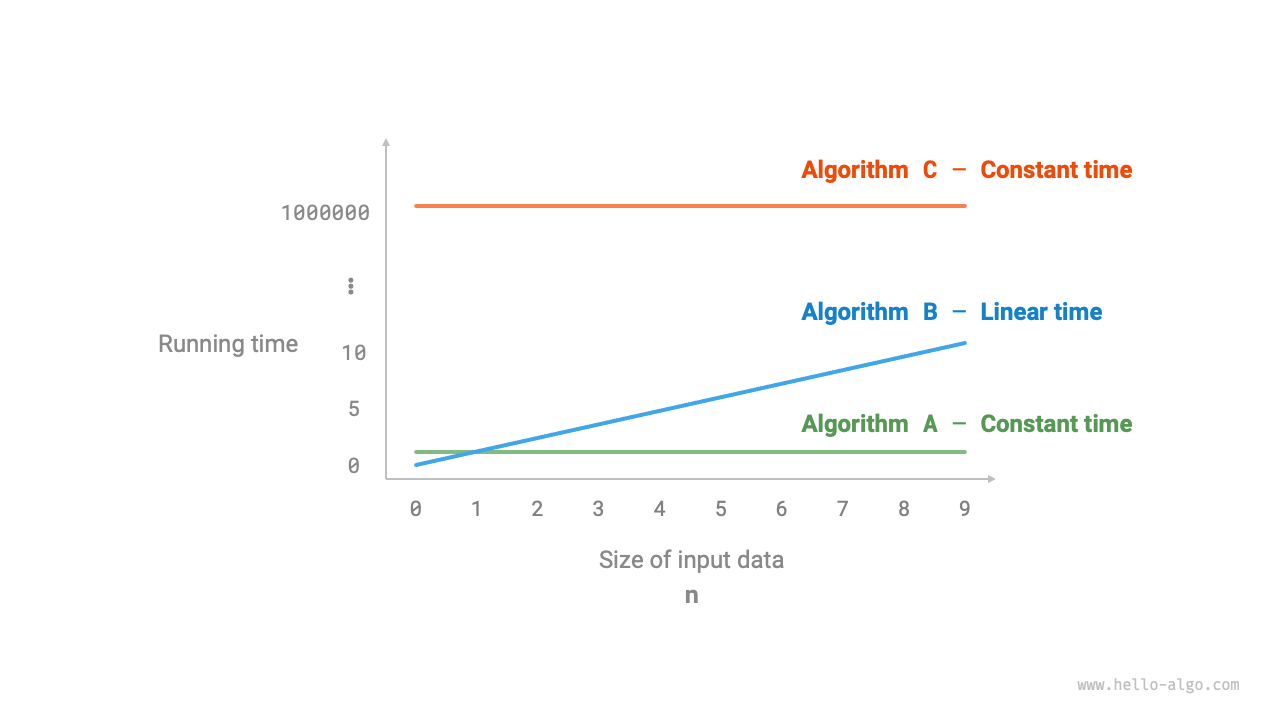
図 2-7 アルゴリズム A、B、C の時間増加傾向
アルゴリズムの実行時間を直接数える方法と比べて、時間計算量分析にはどのような特徴があるでしょうか?
- 時間計算量はアルゴリズム効率を有効に評価できます。例えばアルゴリズム
Bの実行時間は線形に増加するため、\(n > 1\) ではアルゴリズムAより遅く、\(n > 1000000\) ではアルゴリズムCより遅くなります。実際、入力データサイズ \(n\) が十分に大きければ、「定数階」のアルゴリズムは必ず「線形階」のアルゴリズムより優れます。これが実行時間の増加傾向の意味です。 - 時間計算量の見積もり方法はより簡潔です。実行プラットフォームや計算操作の種類は、アルゴリズム実行時間の増加傾向とは無関係です。そのため時間計算量分析では、すべての計算操作の実行時間を同じ「単位時間」とみなしてよく、「計算操作の実行時間を数える」作業を「計算操作の個数を数える」作業へ簡略化できます。これにより見積もりの難易度は大きく下がります。
- 時間計算量には一定の限界もあります。例えばアルゴリズム
AとCの時間計算量は同じでも、実際の実行時間には大きな差があります。同様に、アルゴリズムBの時間計算量はCより高いものの、入力データサイズ \(n\) が小さい場合にはアルゴリズムBのほうが明らかに優れます。このような場合、時間計算量だけでアルゴリズム効率の高低を判断するのは難しいことがあります。もっとも、こうした問題があっても、複雑度分析は依然としてアルゴリズム効率を評価する最も有効で一般的な方法です。
2.3.2 関数の漸近上界¶
入力サイズが \(n\) の次の関数を考えます:
アルゴリズムの操作回数を入力データサイズ \(n\) の関数とし、\(T(n)\) と表すと、上の関数の操作回数は次のようになります:
\(T(n)\) は一次関数であり、実行時間の増加傾向が線形であることを示しています。したがってその時間計算量は線形階です。
線形階の時間計算量を \(O(n)\) と表します。この数学記号はビッグ \(O\) 記法(big-\(O\) notation)と呼ばれ、関数 \(T(n)\) の漸近上界(asymptotic upper bound)を表します。
時間計算量の分析は本質的に「操作回数 \(T(n)\)」の漸近上界を求めることであり、明確な数学的定義があります。
関数の漸近上界
正の実数 \(c\) と実数 \(n_0\) が存在し、すべての \(n > n_0\) について \(T(n) \leq c \cdot f(n)\) が成り立つならば、\(f(n)\) は \(T(n)\) の漸近上界の 1 つであるとみなせます。これを \(T(n) = O(f(n))\) と記します。
下図のように、漸近上界を求めるとは関数 \(f(n)\) を探すことであり、\(n\) が無限大へ近づくときに \(T(n)\) と \(f(n)\) が同じ増加オーダーにあり、定数係数 \(c\) だけが異なる状態を表します。
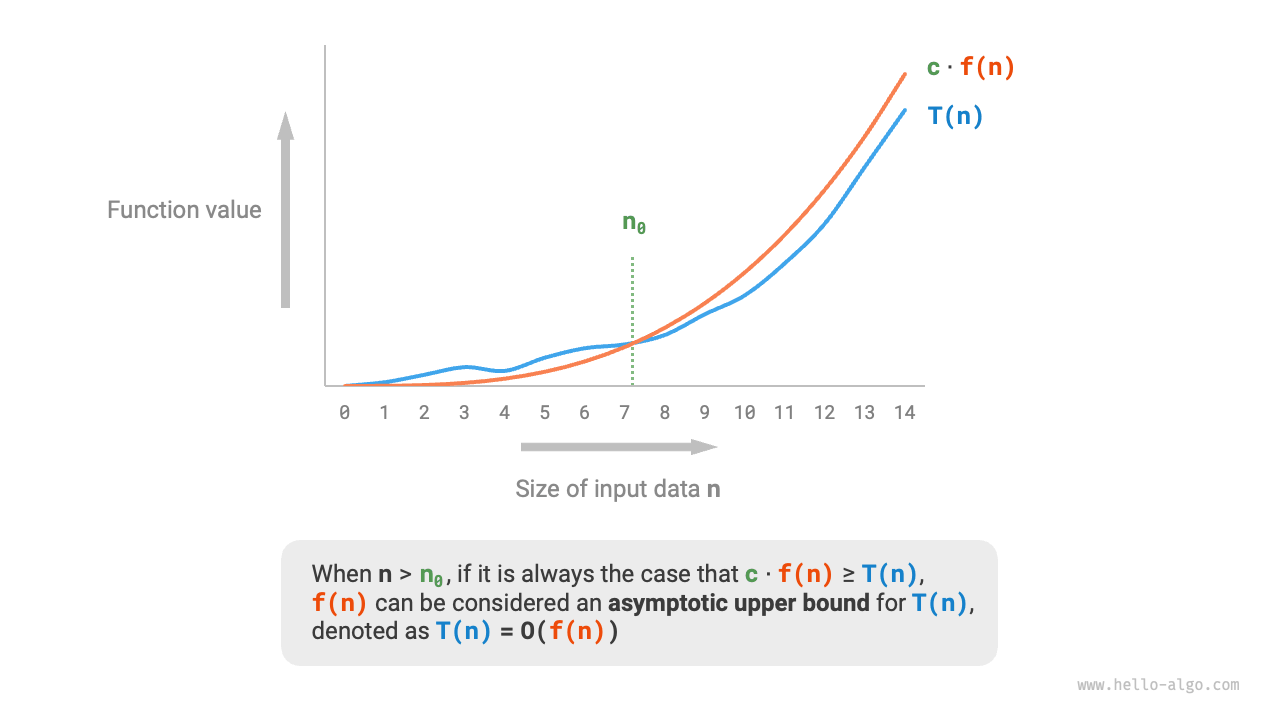
図 2-8 関数の漸近上界
2.3.3 求め方¶
漸近上界はやや数学色が強い概念ですが、完全に理解できていなくても心配はいりません。まずは求め方を押さえ、実践を重ねる中で徐々にその数学的意味をつかめば十分です。
定義より、\(f(n)\) が定まれば時間計算量 \(O(f(n))\) が得られます。では、漸近上界 \(f(n)\) をどのように決めればよいのでしょうか。大きく 2 段階あります。まず操作回数を数え、その後で漸近上界を判断します。
1. 第 1 ステップ:操作回数を数える¶
コードについては、上から下へ 1 行ずつ数えれば十分です。しかし、前述の \(c \cdot f(n)\) における定数係数 \(c\) は任意に大きく取れるため、操作回数 \(T(n)\) に含まれるさまざまな係数や定数項は無視できます。この原則から、次のような簡略化のコツが得られます。
- \(T(n)\) 中の定数を無視する。それらはすべて \(n\) と無関係なので、時間計算量には影響しません。
- すべての係数を省略する。例えば \(2n\) 回や \(5n + 1\) 回のループは、いずれも \(n\) 回と簡略化できます。\(n\) の前の係数は時間計算量に影響しないからです。
- ループが入れ子のときは乗算を使う。総操作回数は外側のループと内側のループの操作回数の積に等しく、各ループ層には引き続き
1.と2.のコツをそれぞれ適用できます。
次の関数では、上記のコツを使って操作回数を数えられます:
次の式は、上記のコツを使う前後の集計結果を示したもので、どちらから求めても時間計算量は \(O(n^2)\) です。
2. 第 2 ステップ:漸近上界を判断する¶
時間計算量は \(T(n)\) の最高次の項によって決まります。これは、\(n\) が無限大に近づくとき、最高次の項が支配的となり、他の項の影響は無視できるからです。
以下の表はその例です。いくつか極端な値を入れているのは、「係数では次数は変わらない」という結論を強調するためです。\(n\) が無限大に近づくと、これらの定数は重要でなくなります。
表 2-2 異なる操作回数に対応する時間計算量
| 操作回数 \(T(n)\) | 時間計算量 \(O(f(n))\) |
|---|---|
| \(100000\) | \(O(1)\) |
| \(3n + 2\) | \(O(n)\) |
| \(2n^2 + 3n + 2\) | \(O(n^2)\) |
| \(n^3 + 10000n^2\) | \(O(n^3)\) |
| \(2^n + 10000n^{10000}\) | \(O(2^n)\) |
2.3.4 よくある種類¶
入力データサイズを \(n\) とすると、よくある時間計算量の種類は次図のとおりです(小さい順に並べています)。
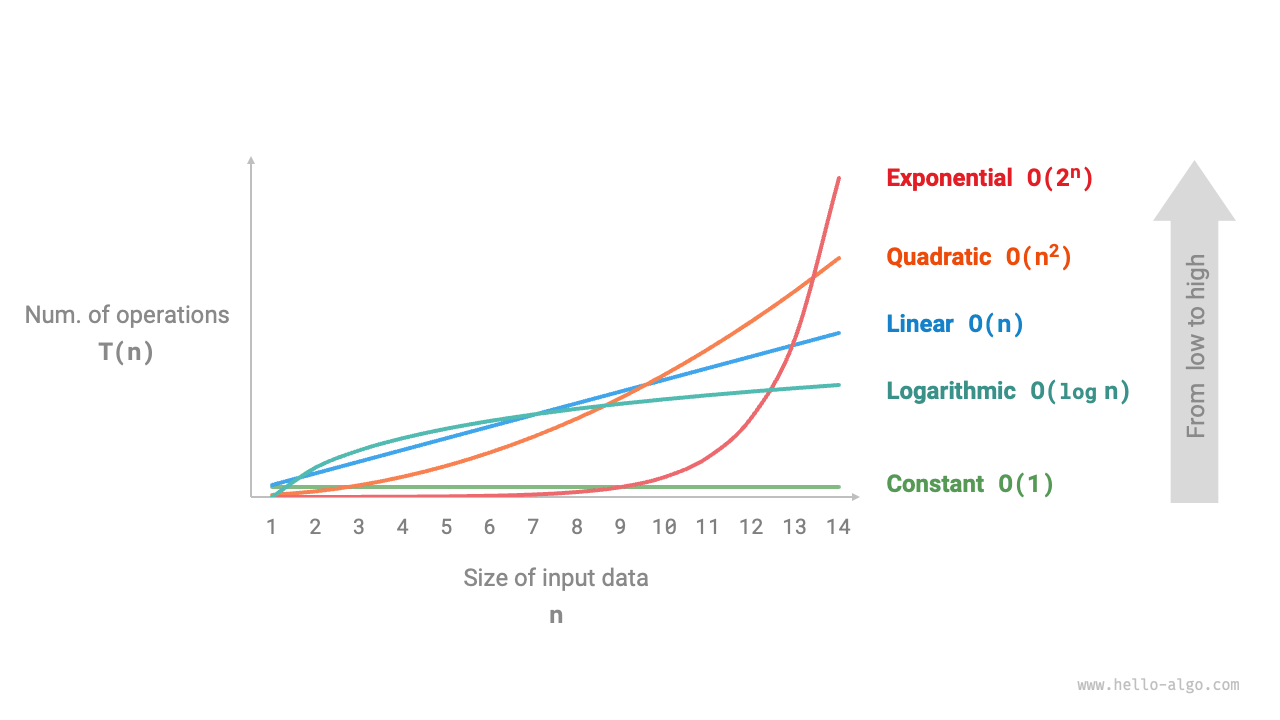
図 2-9 よくある時間計算量の種類
1. 定数階 \(O(1)\)¶
定数階の操作回数は入力データサイズ \(n\) と無関係であり、\(n\) が変化しても増減しません。
次の関数では、操作回数 size が大きい可能性はありますが、入力データサイズ \(n\) とは無関係なので、時間計算量は依然として \(O(1)\) です:
コードの可視化
2. 線形階 \(O(n)\)¶
線形階の操作回数は入力データサイズ \(n\) に対して線形に増加します。線形階は通常、単一ループに現れます:
コードの可視化
配列走査や連結リスト走査などの操作の時間計算量はいずれも \(O(n)\) であり、ここでの \(n\) は配列または連結リストの長さです:
コードの可視化
注意すべきなのは、**入力データサイズ \(n\) は入力データの型に応じて具体的に定める必要がある**ということです。例えば 1 つ目の例では変数 \(n\) が入力データサイズであり、2 つ目の例では配列長 \(n\) がデータサイズです。
3. 平方階 \(O(n^2)\)¶
平方階の操作回数は入力データサイズ \(n\) に対して二乗のオーダーで増加します。平方階は通常、入れ子ループに現れ、外側のループと内側のループの時間計算量がともに \(O(n)\) であるため、全体の時間計算量は \(O(n^2)\) になります:
コードの可視化
以下の図は、定数階・線形階・平方階の 3 種類の時間計算量を比較したものです。
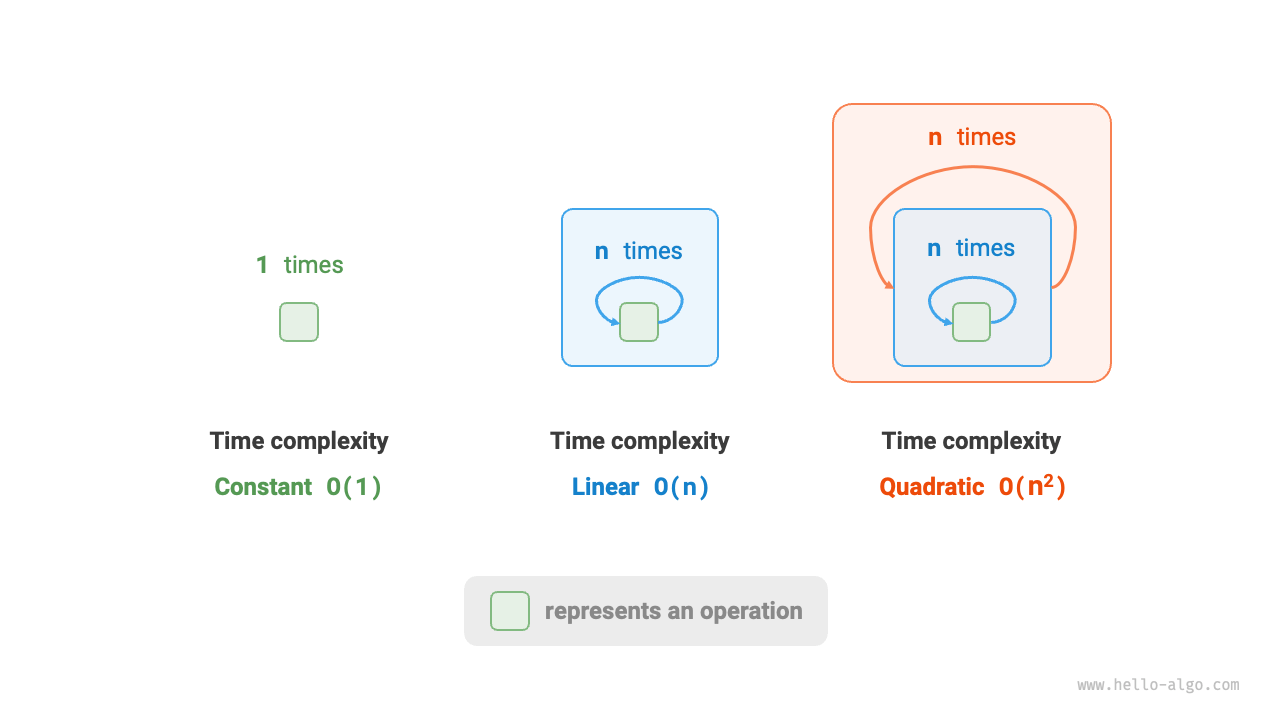
図 2-10 定数階、線形階、平方階の時間計算量
バブルソートを例にとると、外側のループは \(n - 1\) 回実行され、内側のループは \(n-1\)、\(n-2\)、\(\dots\)、\(2\)、\(1\) 回実行され、平均すると \(n / 2\) 回です。したがって時間計算量は \(O((n - 1) n / 2) = O(n^2)\) となります:
def bubble_sort(nums: list[int]) -> int:
"""二次時間(バブルソート)"""
count = 0 # カウンタ
# 外側のループ:未ソート区間は [0, i]
for i in range(len(nums) - 1, 0, -1):
# 内側のループ:未ソート区間 [0, i] の最大要素をその区間の最右端へ交換
for j in range(i):
if nums[j] > nums[j + 1]:
# nums[j] と nums[j + 1] を交換
tmp: int = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 # 要素交換には 3 回の単位操作が含まれる
return count
/* 二次時間(バブルソート) */
int bubbleSort(vector<int> &nums) {
int count = 0; // カウンタ
// 外側のループ:未ソート区間は [0, i]
for (int i = nums.size() - 1; i > 0; i--) {
// 内側のループ:未ソート区間 [0, i] の最大要素をその区間の最右端へ交換
for (int j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// nums[j] と nums[j + 1] を交換
int tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 要素交換には 3 回の単位操作が含まれる
}
}
}
return count;
}
/* 二次時間(バブルソート) */
int bubbleSort(int[] nums) {
int count = 0; // カウンタ
// 外側のループ:未ソート区間は [0, i]
for (int i = nums.length - 1; i > 0; i--) {
// 内側のループ:未ソート区間 [0, i] の最大要素をその区間の最右端へ交換
for (int j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// nums[j] と nums[j + 1] を交換
int tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 要素交換には 3 回の単位操作が含まれる
}
}
}
return count;
}
/* 二次時間(バブルソート) */
int BubbleSort(int[] nums) {
int count = 0; // カウンタ
// 外側のループ:未ソート区間は [0, i]
for (int i = nums.Length - 1; i > 0; i--) {
// 内側のループ:未ソート区間 [0, i] の最大要素をその区間の最右端へ交換
for (int j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// nums[j] と nums[j + 1] を交換
(nums[j + 1], nums[j]) = (nums[j], nums[j + 1]);
count += 3; // 要素交換には 3 回の単位操作が含まれる
}
}
}
return count;
}
/* 二次時間(バブルソート) */
func bubbleSort(nums []int) int {
count := 0 // カウンタ
// 外側のループ:未ソート区間は [0, i]
for i := len(nums) - 1; i > 0; i-- {
// 内側のループ:未ソート区間 [0, i] の最大要素をその区間の最右端へ交換
for j := 0; j < i; j++ {
if nums[j] > nums[j+1] {
// nums[j] と nums[j + 1] を交換
tmp := nums[j]
nums[j] = nums[j+1]
nums[j+1] = tmp
count += 3 // 要素交換には 3 回の単位操作が含まれる
}
}
}
return count
}
/* 二次時間(バブルソート) */
func bubbleSort(nums: inout [Int]) -> Int {
var count = 0 // カウンタ
// 外側のループ:未ソート区間は [0, i]
for i in nums.indices.dropFirst().reversed() {
// 内側のループ:未ソート区間 [0, i] の最大要素をその区間の最右端へ交換
for j in 0 ..< i {
if nums[j] > nums[j + 1] {
// nums[j] と nums[j + 1] を交換
let tmp = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 // 要素交換には 3 回の単位操作が含まれる
}
}
}
return count
}
/* 二次時間(バブルソート) */
function bubbleSort(nums) {
let count = 0; // カウンタ
// 外側のループ:未ソート区間は [0, i]
for (let i = nums.length - 1; i > 0; i--) {
// 内側のループ:未ソート区間 [0, i] の最大要素をその区間の最右端へ交換
for (let j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// nums[j] と nums[j + 1] を交換
let tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 要素交換には 3 回の単位操作が含まれる
}
}
}
return count;
}
/* 二次時間(バブルソート) */
function bubbleSort(nums: number[]): number {
let count = 0; // カウンタ
// 外側のループ:未ソート区間は [0, i]
for (let i = nums.length - 1; i > 0; i--) {
// 内側のループ:未ソート区間 [0, i] の最大要素をその区間の最右端へ交換
for (let j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// nums[j] と nums[j + 1] を交換
let tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 要素交換には 3 回の単位操作が含まれる
}
}
}
return count;
}
/* 二次時間(バブルソート) */
int bubbleSort(List<int> nums) {
int count = 0; // カウンタ
// 外側のループ:未ソート区間は [0, i]
for (var i = nums.length - 1; i > 0; i--) {
// 内側のループ:未ソート区間 [0, i] の最大要素をその区間の最右端へ交換
for (var j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// nums[j] と nums[j + 1] を交換
int tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 要素交換には 3 回の単位操作が含まれる
}
}
}
return count;
}
/* 二次時間(バブルソート) */
fn bubble_sort(nums: &mut [i32]) -> i32 {
let mut count = 0; // カウンタ
// 外側のループ:未ソート区間は [0, i]
for i in (1..nums.len()).rev() {
// 内側のループ:未ソート区間 [0, i] の最大要素をその区間の最右端へ交換
for j in 0..i {
if nums[j] > nums[j + 1] {
// nums[j] と nums[j + 1] を交換
let tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 要素交換には 3 回の単位操作が含まれる
}
}
}
count
}
/* 二次時間(バブルソート) */
int bubbleSort(int *nums, int n) {
int count = 0; // カウンタ
// 外側のループ:未ソート区間は [0, i]
for (int i = n - 1; i > 0; i--) {
// 内側のループ:未ソート区間 [0, i] の最大要素をその区間の最右端へ交換
for (int j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// nums[j] と nums[j + 1] を交換
int tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 要素交換には 3 回の単位操作が含まれる
}
}
}
return count;
}
/* 二次時間(バブルソート) */
fun bubbleSort(nums: IntArray): Int {
var count = 0 // カウンタ
// 外側のループ:未ソート区間は [0, i]
for (i in nums.size - 1 downTo 1) {
// 内側のループ:未ソート区間 [0, i] の最大要素をその区間の最右端へ交換
for (j in 0..<i) {
if (nums[j] > nums[j + 1]) {
// nums[j] と nums[j + 1] を交換
val temp = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = temp
count += 3 // 要素交換には 3 回の単位操作が含まれる
}
}
}
return count
}
### 平方階 ###
def quadratic(n)
count = 0
# ループ回数はデータサイズ n の二乗に比例する
for i in 0...n
for j in 0...n
count += 1
end
end
count
end
# ## 平方階(バブルソート)###
def bubble_sort(nums)
count = 0 # カウンタ
# 外側のループ:未ソート区間は [0, i]
for i in (nums.length - 1).downto(0)
# 内側のループ:未ソート区間 [0, i] の最大要素をその区間の最右端へ交換
for j in 0...i
if nums[j] > nums[j + 1]
# nums[j] と nums[j + 1] を交換
tmp = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 # 要素交換には 3 回の単位操作が含まれる
end
end
end
count
end
コードの可視化
4. 指数階 \(O(2^n)\)¶
生物学における「細胞分裂」は指数階増加の典型例です。初期状態では細胞が \(1\) 個あり、1 回分裂すると \(2\) 個、2 回分裂すると \(4\) 個となり、以下同様に、\(n\) 回分裂すると \(2^n\) 個の細胞になります。
以下の図とコードは細胞分裂の過程を模擬したもので、時間計算量は \(O(2^n)\) です。なお、入力の \(n\) は分裂回数を表し、戻り値 count は総分裂回数を表します。
/* 指数時間(ループ実装) */
function exponential(n: number): number {
let count = 0,
base = 1;
// 細胞は各ラウンドで 2 つに分裂し、数列 1, 2, 4, 8, ..., 2^(n-1) を形成する
for (let i = 0; i < n; i++) {
for (let j = 0; j < base; j++) {
count++;
}
base *= 2;
}
// count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
return count;
}
### 平方階 ###
def quadratic(n)
count = 0
# ループ回数はデータサイズ n の二乗に比例する
for i in 0...n
for j in 0...n
count += 1
end
end
count
end
# ## 平方階(バブルソート)###
def bubble_sort(nums)
count = 0 # カウンタ
# 外側のループ:未ソート区間は [0, i]
for i in (nums.length - 1).downto(0)
# 内側のループ:未ソート区間 [0, i] の最大要素をその区間の最右端へ交換
for j in 0...i
if nums[j] > nums[j + 1]
# nums[j] と nums[j + 1] を交換
tmp = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 # 要素交換には 3 回の単位操作が含まれる
end
end
end
count
end
# ## 指数階(ループ実装)###
def exponential(n)
count, base = 0, 1
# 細胞は各ラウンドで 2 つに分裂し、数列 1, 2, 4, 8, ..., 2^(n-1) を形成する
(0...n).each do
(0...base).each { count += 1 }
base *= 2
end
# count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
count
end
コードの可視化
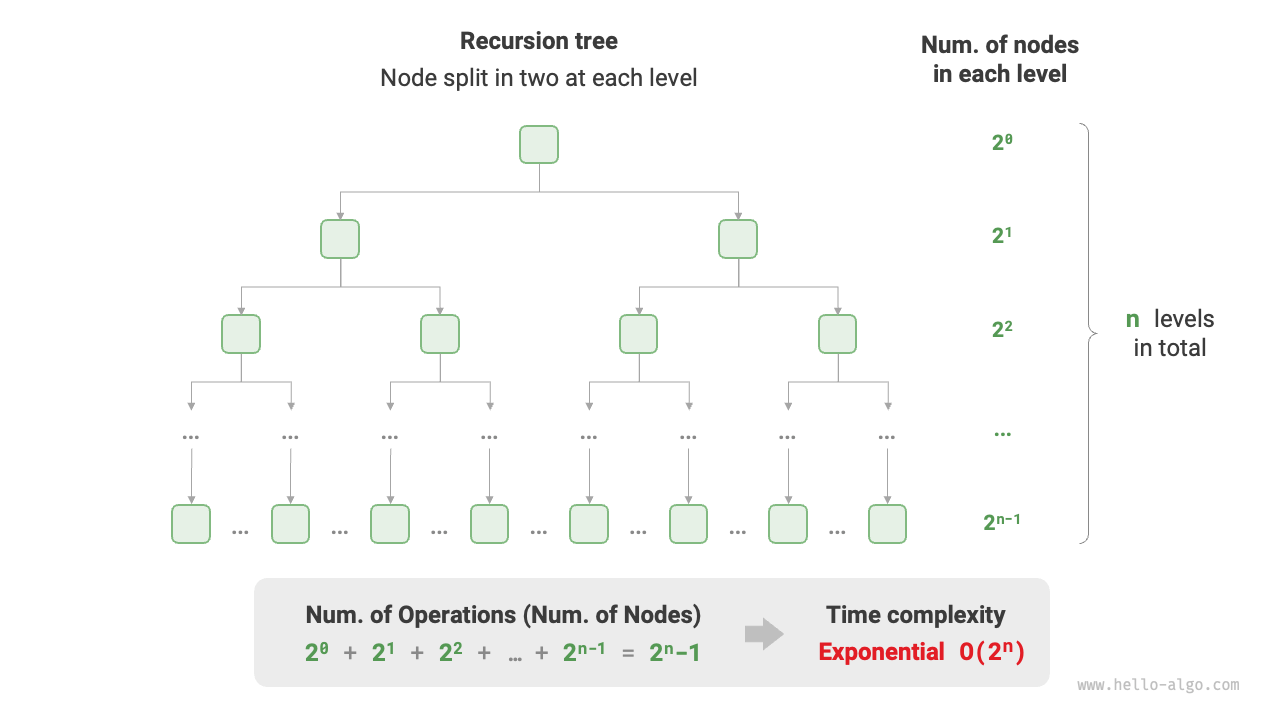
図 2-11 指数階の時間計算量
実際のアルゴリズムでも、指数階は再帰関数によく現れます。例えば次のコードでは、再帰的に 2 つへ分岐し、\(n\) 回分裂した後に停止します:
### 平方階 ###
def quadratic(n)
count = 0
# ループ回数はデータサイズ n の二乗に比例する
for i in 0...n
for j in 0...n
count += 1
end
end
count
end
# ## 平方階(バブルソート)###
def bubble_sort(nums)
count = 0 # カウンタ
# 外側のループ:未ソート区間は [0, i]
for i in (nums.length - 1).downto(0)
# 内側のループ:未ソート区間 [0, i] の最大要素をその区間の最右端へ交換
for j in 0...i
if nums[j] > nums[j + 1]
# nums[j] と nums[j + 1] を交換
tmp = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 # 要素交換には 3 回の単位操作が含まれる
end
end
end
count
end
# ## 指数階(ループ実装)###
def exponential(n)
count, base = 0, 1
# 細胞は各ラウンドで 2 つに分裂し、数列 1, 2, 4, 8, ..., 2^(n-1) を形成する
(0...n).each do
(0...base).each { count += 1 }
base *= 2
end
# count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
count
end
# ## 指数階(再帰実装)###
def exp_recur(n)
return 1 if n == 1
exp_recur(n - 1) + exp_recur(n - 1) + 1
end
コードの可視化
指数階の増加は非常に速く、全探索法(ブルートフォース、バックトラッキングなど)によく見られます。データ規模が大きい問題では、指数階は受け入れられず、通常は動的計画法や貪欲法などを使って解く必要があります。
5. 対数階 \(O(\log n)\)¶
指数階とは逆に、対数階は「各ラウンドで半分になる」状況を表します。入力データサイズを \(n\) とすると、各ラウンドで半減するため、ループ回数は \(\log_2 n\)、すなわち \(2^n\) の逆関数になります。
以下の図とコードは、「各ラウンドで半分になる」過程を模擬したもので、時間計算量は \(O(\log_2 n)\)、簡潔には \(O(\log n)\) と書きます:
### 平方階 ###
def quadratic(n)
count = 0
# ループ回数はデータサイズ n の二乗に比例する
for i in 0...n
for j in 0...n
count += 1
end
end
count
end
# ## 平方階(バブルソート)###
def bubble_sort(nums)
count = 0 # カウンタ
# 外側のループ:未ソート区間は [0, i]
for i in (nums.length - 1).downto(0)
# 内側のループ:未ソート区間 [0, i] の最大要素をその区間の最右端へ交換
for j in 0...i
if nums[j] > nums[j + 1]
# nums[j] と nums[j + 1] を交換
tmp = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 # 要素交換には 3 回の単位操作が含まれる
end
end
end
count
end
# ## 指数階(ループ実装)###
def exponential(n)
count, base = 0, 1
# 細胞は各ラウンドで 2 つに分裂し、数列 1, 2, 4, 8, ..., 2^(n-1) を形成する
(0...n).each do
(0...base).each { count += 1 }
base *= 2
end
# count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
count
end
# ## 指数階(再帰実装)###
def exp_recur(n)
return 1 if n == 1
exp_recur(n - 1) + exp_recur(n - 1) + 1
end
# ## 対数階(ループ実装)###
def logarithmic(n)
count = 0
while n > 1
n /= 2
count += 1
end
count
end
コードの可視化
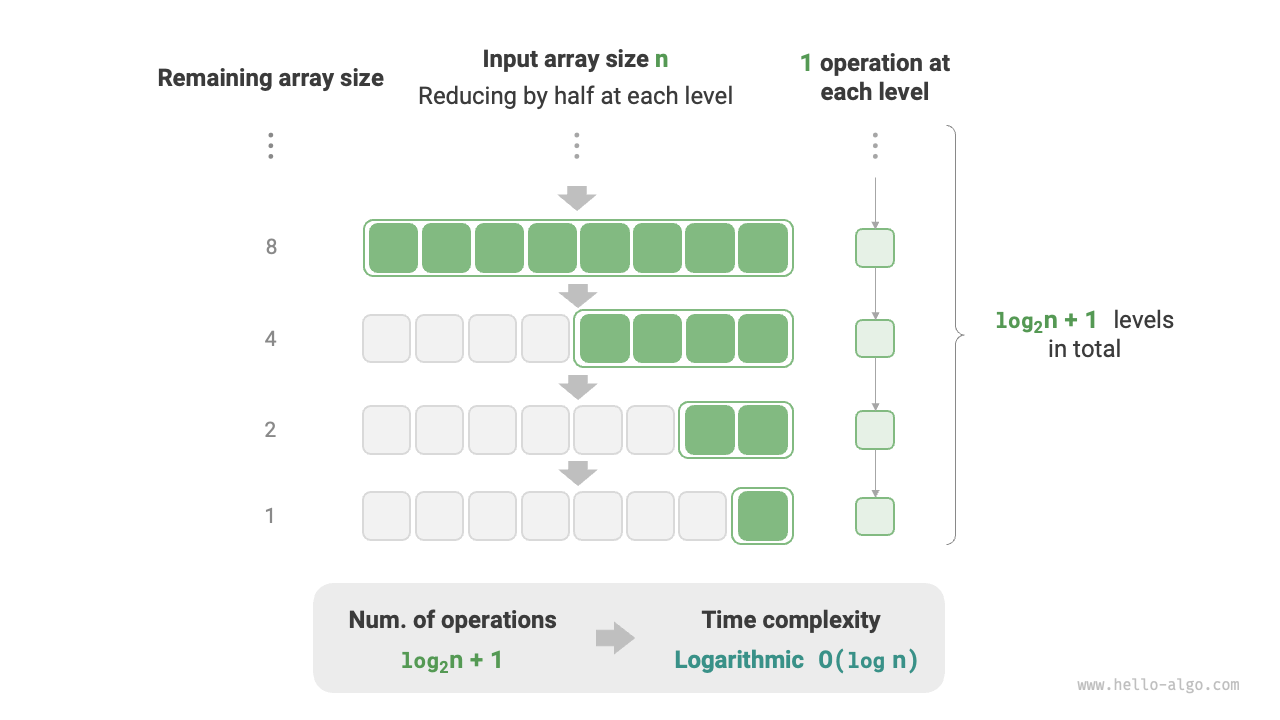
図 2-12 対数階の時間計算量
指数階と同様に、対数階も再帰関数によく現れます。次のコードは高さ \(\log_2 n\) の再帰木を形成します:
### 平方階 ###
def quadratic(n)
count = 0
# ループ回数はデータサイズ n の二乗に比例する
for i in 0...n
for j in 0...n
count += 1
end
end
count
end
# ## 平方階(バブルソート)###
def bubble_sort(nums)
count = 0 # カウンタ
# 外側のループ:未ソート区間は [0, i]
for i in (nums.length - 1).downto(0)
# 内側のループ:未ソート区間 [0, i] の最大要素をその区間の最右端へ交換
for j in 0...i
if nums[j] > nums[j + 1]
# nums[j] と nums[j + 1] を交換
tmp = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 # 要素交換には 3 回の単位操作が含まれる
end
end
end
count
end
# ## 指数階(ループ実装)###
def exponential(n)
count, base = 0, 1
# 細胞は各ラウンドで 2 つに分裂し、数列 1, 2, 4, 8, ..., 2^(n-1) を形成する
(0...n).each do
(0...base).each { count += 1 }
base *= 2
end
# count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
count
end
# ## 指数階(再帰実装)###
def exp_recur(n)
return 1 if n == 1
exp_recur(n - 1) + exp_recur(n - 1) + 1
end
# ## 対数階(ループ実装)###
def logarithmic(n)
count = 0
while n > 1
n /= 2
count += 1
end
count
end
# ## 対数階(再帰実装)###
def log_recur(n)
return 0 unless n > 1
log_recur(n / 2) + 1
end
コードの可視化
対数階は分割統治に基づくアルゴリズムによく現れ、「1 つを複数に分ける」「複雑なものを単純化する」という考え方を体現しています。増加は緩やかで、定数階に次いで理想的な時間計算量です。
\(O(\log n)\) の底は何か?
正確には、「\(m\) 個に分ける」場合に対応する時間計算量は \(O(\log_m n)\) です。そして対数の底の変換公式により、底が異なっても同値な時間計算量が得られます:
つまり、底 \(m\) は複雑度に影響を与えずに変換できます。そのため通常は底 \(m\) を省略し、対数階を単に \(O(\log n)\) と記します。
6. 線形対数階 \(O(n \log n)\)¶
線形対数階は入れ子ループによく現れ、2 層のループの時間計算量はそれぞれ \(O(\log n)\) と \(O(n)\) です。関連するコードは次のとおりです:
コードの可視化
下図は線形対数階がどのように生じるかを示しています。二分木の各層の操作総数はすべて \(n\) であり、木全体は \(\log_2 n + 1\) 層あるため、時間計算量は \(O(n \log n)\) です。
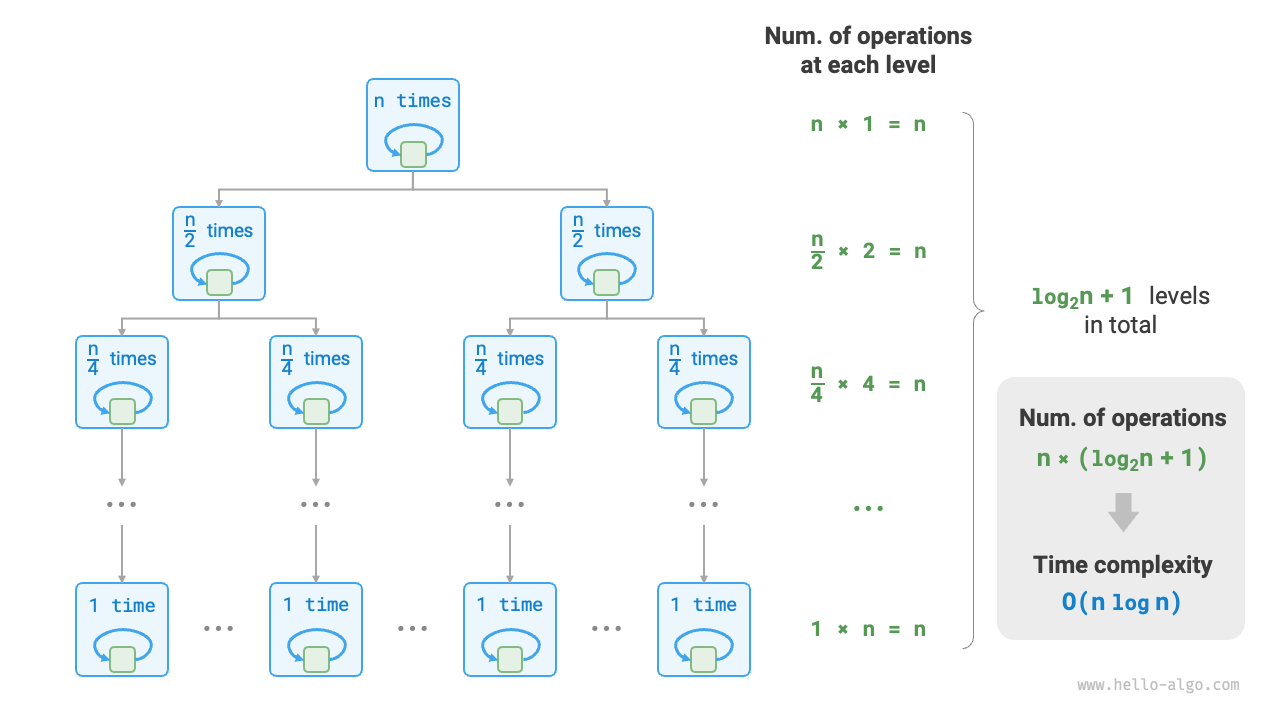
図 2-13 線形対数階の時間計算量
主なソートアルゴリズムの時間計算量は通常 \(O(n \log n)\) であり、例えばクイックソート、マージソート、ヒープソートなどがあります。
7. 階乗階 \(O(n!)\)¶
階乗階は、数学における「全順列」の問題に対応します。互いに重複しない \(n\) 個の要素が与えられたとき、そのすべての並べ方を求めると、通り数は次のようになります:
階乗は通常、再帰で実装されます。以下の図とコードのように、第 1 層では \(n\) 個に分岐し、第 2 層では \(n - 1\) 個に分岐し、以下同様に、第 \(n\) 層で分岐が停止します:
### 線形対数時間 ###
def linear_log_recur(n)
return 1 unless n > 1
count = linear_log_recur(n / 2) + linear_log_recur(n / 2)
(0...n).each { count += 1 }
count
end
# ## 階乗階(再帰実装)###
def factorial_recur(n)
return 1 if n == 0
count = 0
# 1個から n 個に分裂
(0...n).each { count += factorial_recur(n - 1) }
count
end
コードの可視化
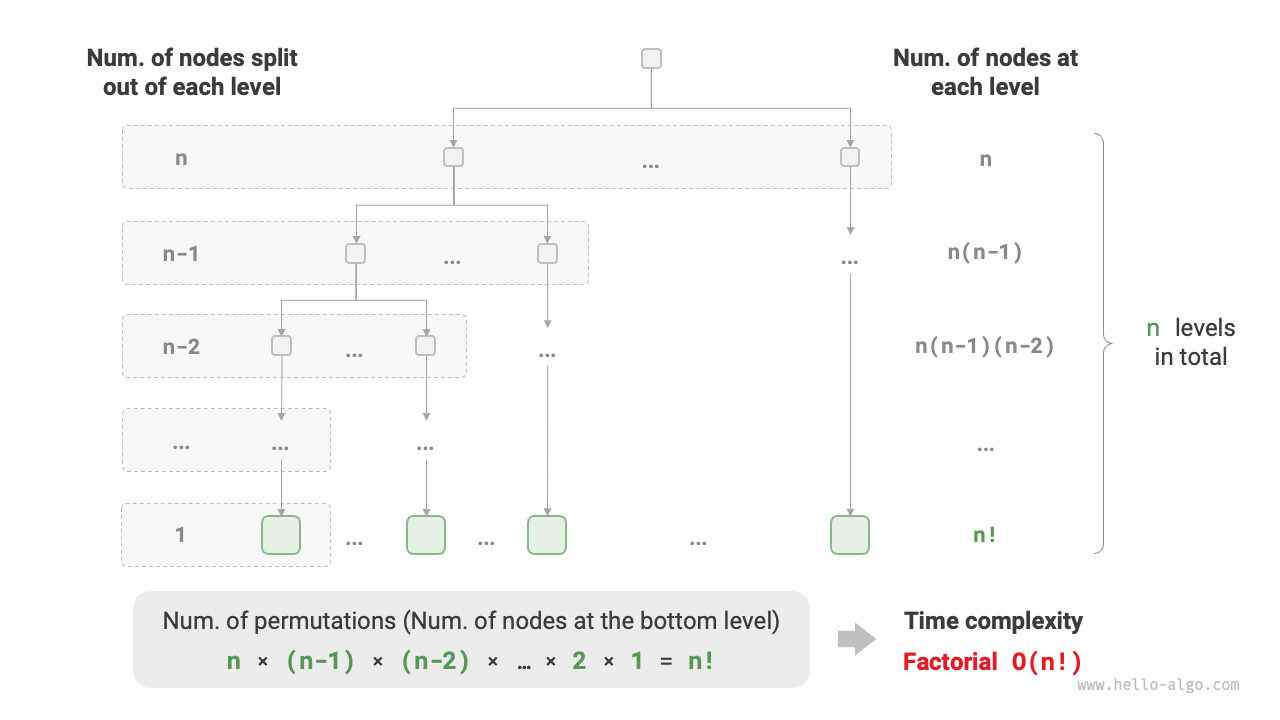
図 2-14 階乗階の時間計算量
注意すべき点として、\(n \geq 4\) なら常に \(n! > 2^n\) なので、階乗階は指数階よりもさらに速く増加し、\(n\) が大きい場合にはやはり受け入れられません。
2.3.5 最悪・最良・平均時間計算量¶
アルゴリズムの時間効率は固定ではなく、入力データの分布に左右されることが多いです。長さ \(n\) の配列 nums を考えます。nums は \(1\) から \(n\) までの数字で構成され、各数字は 1 回だけ現れます。ただし要素の順序はランダムにシャッフルされており、目標は要素 \(1\) のインデックスを返すことです。ここから次の結論が得られます。
nums = [?, ?, ..., 1]、つまり末尾の要素が \(1\) の場合は、配列全体を最後まで走査する必要があり、最悪時間計算量 \(O(n)\) になります。nums = [1, ?, ?, ...]、つまり先頭要素が \(1\) の場合は、配列がどれだけ長くてもそれ以上走査する必要がなく、最良時間計算量 \(\Omega(1)\) になります。
「最悪時間計算量」は関数の漸近上界に対応し、ビッグ \(O\) 記法で表します。同様に、「最良時間計算量」は関数の漸近下界に対応し、\(\Omega\) 記法で表します:
def random_numbers(n: int) -> list[int]:
"""要素が 1, 2, ..., n で順序がシャッフルされた配列を生成する"""
# 配列 nums =: 1, 2, 3, ..., n を生成する
nums = [i for i in range(1, n + 1)]
# 配列要素をランダムにシャッフル
random.shuffle(nums)
return nums
def find_one(nums: list[int]) -> int:
"""配列 nums 内で数値 1 のインデックスを探す"""
for i in range(len(nums)):
# 要素 1 が配列の先頭にあるとき、最良時間計算量 O(1) となる
# 要素 1 が配列の末尾にあるとき、最悪時間計算量 O(n) となる
if nums[i] == 1:
return i
return -1
/* 要素が { 1, 2, ..., n } で、順序がシャッフルされた配列を生成 */
vector<int> randomNumbers(int n) {
vector<int> nums(n);
// 配列 nums = { 1, 2, 3, ..., n } を生成
for (int i = 0; i < n; i++) {
nums[i] = i + 1;
}
// システム時刻を使って乱数シードを生成する
unsigned seed = chrono::system_clock::now().time_since_epoch().count();
// 配列要素をランダムにシャッフル
shuffle(nums.begin(), nums.end(), default_random_engine(seed));
return nums;
}
/* 配列 nums 内で数値 1 のインデックスを探す */
int findOne(vector<int> &nums) {
for (int i = 0; i < nums.size(); i++) {
// 要素 1 が配列の先頭にあるとき、最良時間計算量 O(1) となる
// 要素 1 が配列の末尾にあるとき、最悪時間計算量 O(n) となる
if (nums[i] == 1)
return i;
}
return -1;
}
/* 要素が { 1, 2, ..., n } で、順序がシャッフルされた配列を生成 */
int[] randomNumbers(int n) {
Integer[] nums = new Integer[n];
// 配列 nums = { 1, 2, 3, ..., n } を生成
for (int i = 0; i < n; i++) {
nums[i] = i + 1;
}
// 配列要素をランダムにシャッフル
Collections.shuffle(Arrays.asList(nums));
// Integer[] -> int[]
int[] res = new int[n];
for (int i = 0; i < n; i++) {
res[i] = nums[i];
}
return res;
}
/* 配列 nums 内で数値 1 のインデックスを探す */
int findOne(int[] nums) {
for (int i = 0; i < nums.length; i++) {
// 要素 1 が配列の先頭にあるとき、最良時間計算量 O(1) となる
// 要素 1 が配列の末尾にあるとき、最悪時間計算量 O(n) となる
if (nums[i] == 1)
return i;
}
return -1;
}
/* 要素が { 1, 2, ..., n } で、順序がシャッフルされた配列を生成 */
int[] RandomNumbers(int n) {
int[] nums = new int[n];
// 配列 nums = { 1, 2, 3, ..., n } を生成
for (int i = 0; i < n; i++) {
nums[i] = i + 1;
}
// 配列要素をランダムにシャッフル
for (int i = 0; i < nums.Length; i++) {
int index = new Random().Next(i, nums.Length);
(nums[i], nums[index]) = (nums[index], nums[i]);
}
return nums;
}
/* 配列 nums 内で数値 1 のインデックスを探す */
int FindOne(int[] nums) {
for (int i = 0; i < nums.Length; i++) {
// 要素 1 が配列の先頭にあるとき、最良時間計算量 O(1) となる
// 要素 1 が配列の末尾にあるとき、最悪時間計算量 O(n) となる
if (nums[i] == 1)
return i;
}
return -1;
}
/* 要素が { 1, 2, ..., n } で、順序がシャッフルされた配列を生成 */
func randomNumbers(n int) []int {
nums := make([]int, n)
// 配列 nums = { 1, 2, 3, ..., n } を生成
for i := 0; i < n; i++ {
nums[i] = i + 1
}
// 配列要素をランダムにシャッフル
rand.Shuffle(len(nums), func(i, j int) {
nums[i], nums[j] = nums[j], nums[i]
})
return nums
}
/* 配列 nums 内で数値 1 のインデックスを探す */
func findOne(nums []int) int {
for i := 0; i < len(nums); i++ {
// 要素 1 が配列の先頭にあるとき、最良時間計算量 O(1) となる
// 要素 1 が配列の末尾にあるとき、最悪時間計算量 O(n) となる
if nums[i] == 1 {
return i
}
}
return -1
}
/* 要素が { 1, 2, ..., n } で、順序がシャッフルされた配列を生成 */
func randomNumbers(n: Int) -> [Int] {
// 配列 nums = { 1, 2, 3, ..., n } を生成
var nums = Array(1 ... n)
// 配列要素をランダムにシャッフル
nums.shuffle()
return nums
}
/* 配列 nums 内で数値 1 のインデックスを探す */
func findOne(nums: [Int]) -> Int {
for i in nums.indices {
// 要素 1 が配列の先頭にあるとき、最良時間計算量 O(1) となる
// 要素 1 が配列の末尾にあるとき、最悪時間計算量 O(n) となる
if nums[i] == 1 {
return i
}
}
return -1
}
/* 要素が { 1, 2, ..., n } で、順序がシャッフルされた配列を生成 */
function randomNumbers(n) {
const nums = Array(n);
// 配列 nums = { 1, 2, 3, ..., n } を生成
for (let i = 0; i < n; i++) {
nums[i] = i + 1;
}
// 配列要素をランダムにシャッフル
for (let i = 0; i < n; i++) {
const r = Math.floor(Math.random() * (i + 1));
const temp = nums[i];
nums[i] = nums[r];
nums[r] = temp;
}
return nums;
}
/* 配列 nums 内で数値 1 のインデックスを探す */
function findOne(nums) {
for (let i = 0; i < nums.length; i++) {
// 要素 1 が配列の先頭にあるとき、最良時間計算量 O(1) となる
// 要素 1 が配列の末尾にあるとき、最悪時間計算量 O(n) となる
if (nums[i] === 1) {
return i;
}
}
return -1;
}
/* 要素が { 1, 2, ..., n } で、順序がシャッフルされた配列を生成 */
function randomNumbers(n: number): number[] {
const nums = Array(n);
// 配列 nums = { 1, 2, 3, ..., n } を生成
for (let i = 0; i < n; i++) {
nums[i] = i + 1;
}
// 配列要素をランダムにシャッフル
for (let i = 0; i < n; i++) {
const r = Math.floor(Math.random() * (i + 1));
const temp = nums[i];
nums[i] = nums[r];
nums[r] = temp;
}
return nums;
}
/* 配列 nums 内で数値 1 のインデックスを探す */
function findOne(nums: number[]): number {
for (let i = 0; i < nums.length; i++) {
// 要素 1 が配列の先頭にあるとき、最良時間計算量 O(1) となる
// 要素 1 が配列の末尾にあるとき、最悪時間計算量 O(n) となる
if (nums[i] === 1) {
return i;
}
}
return -1;
}
/* 要素が { 1, 2, ..., n } で、順序がシャッフルされた配列を生成 */
List<int> randomNumbers(int n) {
final nums = List.filled(n, 0);
// 配列 nums = { 1, 2, 3, ..., n } を生成
for (var i = 0; i < n; i++) {
nums[i] = i + 1;
}
// 配列要素をランダムにシャッフル
nums.shuffle();
return nums;
}
/* 配列 nums 内で数値 1 のインデックスを探す */
int findOne(List<int> nums) {
for (var i = 0; i < nums.length; i++) {
// 要素 1 が配列の先頭にあるとき、最良時間計算量 O(1) となる
// 要素 1 が配列の末尾にあるとき、最悪時間計算量 O(n) となる
if (nums[i] == 1) return i;
}
return -1;
}
/* 要素が { 1, 2, ..., n } で、順序がシャッフルされた配列を生成 */
fn random_numbers(n: i32) -> Vec<i32> {
// 配列 nums = { 1, 2, 3, ..., n } を生成
let mut nums = (1..=n).collect::<Vec<i32>>();
// 配列要素をランダムにシャッフル
nums.shuffle(&mut thread_rng());
nums
}
/* 配列 nums 内で数値 1 のインデックスを探す */
fn find_one(nums: &[i32]) -> Option<usize> {
for i in 0..nums.len() {
// 要素 1 が配列の先頭にあるとき、最良時間計算量 O(1) となる
// 要素 1 が配列の末尾にあるとき、最悪時間計算量 O(n) となる
if nums[i] == 1 {
return Some(i);
}
}
None
}
/* 要素が { 1, 2, ..., n } で、順序がシャッフルされた配列を生成 */
int *randomNumbers(int n) {
// ヒープ領域にメモリを確保する(要素数 n、要素型 int の一次元可変長配列を作成)
int *nums = (int *)malloc(n * sizeof(int));
// 配列 nums = { 1, 2, 3, ..., n } を生成
for (int i = 0; i < n; i++) {
nums[i] = i + 1;
}
// 配列要素をランダムにシャッフル
for (int i = n - 1; i > 0; i--) {
int j = rand() % (i + 1);
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
return nums;
}
/* 配列 nums 内で数値 1 のインデックスを探す */
int findOne(int *nums, int n) {
for (int i = 0; i < n; i++) {
// 要素 1 が配列の先頭にあるとき、最良時間計算量 O(1) となる
// 要素 1 が配列の末尾にあるとき、最悪時間計算量 O(n) となる
if (nums[i] == 1)
return i;
}
return -1;
}
/* 要素が { 1, 2, ..., n } で、順序がシャッフルされた配列を生成 */
fun randomNumbers(n: Int): Array<Int?> {
val nums = IntArray(n)
// 配列 nums = { 1, 2, 3, ..., n } を生成
for (i in 0..<n) {
nums[i] = i + 1
}
// 配列要素をランダムにシャッフル
nums.shuffle()
val res = arrayOfNulls<Int>(n)
for (i in 0..<n) {
res[i] = nums[i]
}
return res
}
/* 配列 nums 内で数値 1 のインデックスを探す */
fun findOne(nums: Array<Int?>): Int {
for (i in nums.indices) {
// 要素 1 が配列の先頭にあるとき、最良時間計算量 O(1) となる
// 要素 1 が配列の末尾にあるとき、最悪時間計算量 O(n) となる
if (nums[i] == 1)
return i
}
return -1
}
### 1, 2, ..., n を要素とする配列を生成し、順序をシャッフルする ###
def random_numbers(n)
# 配列 nums =: 1, 2, 3, ..., n を生成する
nums = Array.new(n) { |i| i + 1 }
# 配列要素をランダムにシャッフル
nums.shuffle!
end
### 配列 nums 内の数値 1 のインデックスを探す ###
def find_one(nums)
for i in 0...nums.length
# 要素 1 が配列の先頭にあるとき、最良時間計算量 O(1) となる
# 要素 1 が配列の末尾にあるとき、最悪時間計算量 O(n) となる
return i if nums[i] == 1
end
-1
end
コードの可視化
実際には、最良時間計算量を使うことはあまりありません。通常それが実現する確率はごく低く、誤解を招く可能性があるからです。**一方で最悪時間計算量はより実用的で、効率の安全側の目安を与えてくれる**ため、安心してアルゴリズムを使えます。
上の例から分かるように、最悪時間計算量と最良時間計算量は「特殊なデータ分布」でのみ現れ、その発生確率は低いことが多く、アルゴリズムの実行効率をそのまま正確に反映するわけではありません。それに対して、**平均時間計算量はランダム入力におけるアルゴリズムの実行効率を表せる**ため、\(\Theta\) 記法で表します。
一部のアルゴリズムでは、ランダムなデータ分布における平均的な状況を比較的簡単に求められます。例えば上の例では、入力配列はシャッフルされているため、要素 \(1\) が任意のインデックスに現れる確率は等しいです。したがってアルゴリズムの平均ループ回数は配列長の半分 \(n / 2\) となり、平均時間計算量は \(\Theta(n / 2) = \Theta(n)\) です。
しかし、より複雑なアルゴリズムでは、平均時間計算量を計算するのはしばしば困難です。データ分布に対する全体の数学的期待値を分析するのが難しいからです。そのような場合、通常は最悪時間計算量をアルゴリズム効率の評価基準として用います。
なぜ \(\Theta\) 記号をあまり見かけないのか?
おそらく \(O\) 記号のほうが口にしやすいため、平均時間計算量を表すのにもよく使われます。ただし厳密には、この用法は正確ではありません。本書や他の資料で「平均時間計算量 \(O(n)\)」のような表現を見かけた場合は、そのまま \(\Theta(n)\) と理解してください。