2.2 反復と再帰¶
アルゴリズムでは、ある処理を繰り返し実行することがよくあり、これは複雑度解析と密接に関係しています。そのため、時間計算量と空間計算量を紹介する前に、まずプログラム内で反復実行を実現する方法、つまり 2 つの基本的な制御構造である反復と再帰について見ていきます。
2.2.1 反復¶
反復(iteration)は、ある処理を繰り返し実行するための制御構造です。反復では、プログラムは一定の条件を満たす間、あるコード片を繰り返し実行し、その条件を満たさなくなるまで続けます。
1. for ループ¶
for ループは最も一般的な反復形式の 1 つで、反復回数があらかじめ分かっている場合に適しています。
次の関数は for ループを用いて \(1 + 2 + \dots + n\) の総和を計算しており、その結果は変数 res に記録されます。なお、Python の range(a, b) に対応する区間は「左閉右開」であり、走査範囲は \(a, a + 1, \dots, b-1\) です。
コードの可視化
次の図は、この総和関数のフローチャートです。
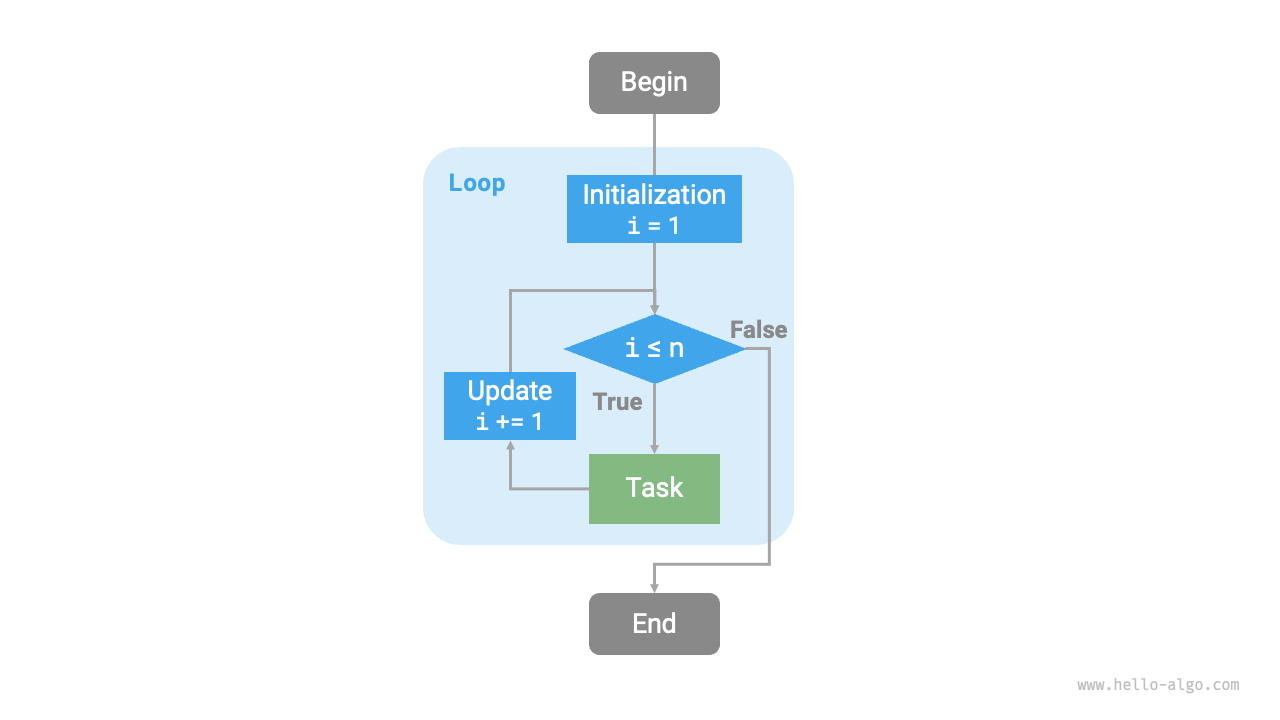
図 2-1 総和関数のフローチャート
この総和関数の操作回数は入力データサイズ \(n\) に比例し、言い換えれば「線形関係」にあります。実際、時間計算量が記述するのはこの「線形関係」そのものです。関連内容は次節で詳しく説明します。
2. while ループ¶
for ループと同様に、while ループも反復を実現する方法の 1 つです。while ループでは、各反復のたびにまず条件を確認し、条件が真であれば実行を続け、そうでなければループを終了します。
次に、while ループを使って \(1 + 2 + \dots + n\) の総和を求めてみましょう。
コードの可視化
**while ループは for ループより自由度が高い**です。while ループでは、条件変数の初期化や更新手順を柔軟に設計できます。
たとえば次のコードでは、条件変数 \(i\) が各反復で 2 回更新されており、このようなケースは for ループではあまり扱いやすくありません。
### while ループ ###
def while_loop(n)
res = 0
i = 1 # 条件変数を初期化する
# 1, 2, ..., n-1, n を順に加算する
while i <= n
res += i
i += 1 # 条件変数を更新する
end
res
end
# ## while ループ(2 回更新)###
def while_loop_ii(n)
res = 0
i = 1 # 条件変数を初期化する
# 1, 4, 10, ... を順に加算する
while i <= n
res += i
# 条件変数を更新する
i += 1
i *= 2
end
res
end
コードの可視化
総じて、**for ループのコードはより簡潔で、while ループはより柔軟**です。どちらも反復構造を実現できますが、どちらを使うかは問題ごとの要件に応じて決めるべきです。
3. ネストしたループ¶
1 つのループ構造の中に別のループ構造を入れ子にできます。以下では for ループを例にします。
/* 二重 for ループ */
char *nestedForLoop(int n) {
// n * n は対応する点の個数であり、"(i, j), " に対応する文字列長の最大は 6+10*2 で、さらに末尾の空文字 \0 のための追加領域が必要
int size = n * n * 26 + 1;
char *res = malloc(size * sizeof(char));
// i = 1, 2, ..., n-1, n とループする
for (int i = 1; i <= n; i++) {
// j = 1, 2, ..., n-1, n とループする
for (int j = 1; j <= n; j++) {
char tmp[26];
snprintf(tmp, sizeof(tmp), "(%d, %d), ", i, j);
strncat(res, tmp, size - strlen(res) - 1);
}
}
return res;
}
コードの可視化
次の図は、このネストしたループのフローチャートです。
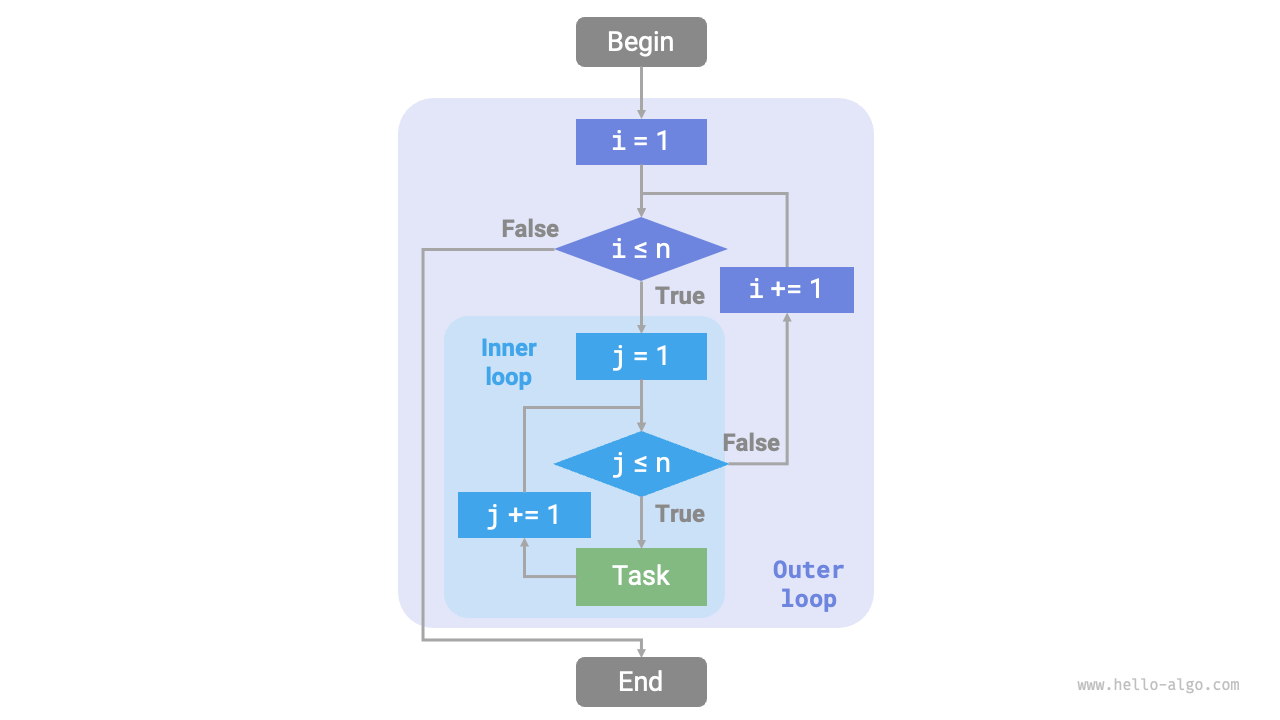
図 2-2 ネストしたループのフローチャート
この場合、関数の操作回数は \(n^2\) に比例し、言い換えればアルゴリズムの実行時間は入力データサイズ \(n\) と「二次関係」にあります。
さらにネストしたループを追加することもできます。ネストが 1 段増えるたびに「次元が 1 つ上がる」ことになり、時間計算量は「三次関係」「四次関係」へと高くなっていきます。
2.2.2 再帰¶
再帰(recursion)は、関数が自分自身を呼び出すことで問題を解決するアルゴリズム戦略です。主に 2 つの段階から成ります。
- 再帰呼び出し:プログラムは自分自身をより深く呼び出し続け、通常はより小さい、またはより単純化された引数を渡し、「終了条件」に達するまで進みます。
- 復帰: 「終了条件」が満たされると、プログラムは最も深い再帰関数から 1 層ずつ戻り、各層の結果をまとめていきます。
実装の観点から見ると、再帰コードは主に 3 つの要素から成ります。
- 終了条件:いつ再帰呼び出しから復帰へ切り替わるかを決めます。
- 再帰呼び出し:再帰呼び出しに対応し、関数が自分自身を呼び出します。通常はより小さい、またはより単純化された引数を入力します。
- 結果の返却:復帰に対応し、現在の再帰レベルの結果を 1 つ上の層へ返します。
次のコードを見ると、関数 recur(n) を呼び出すだけで \(1 + 2 + \dots + n\) を計算できます。
コードの可視化
次の図は、この関数の再帰過程を示しています。

図 2-3 総和関数の再帰過程
計算の観点では、反復と再帰は同じ結果を得られますが、それらは問題を考え解決するためのまったく異なる 2 つのパラダイムを表しています。
- 反復:「ボトムアップ」で問題を解決します。最も基本的な手順から始め、それらを繰り返したり積み上げたりして、処理が完了するまで進めます。
- 再帰:「トップダウン」で問題を解決します。元の問題をより小さな部分問題に分解し、それらの部分問題は元の問題と同じ形を持ちます。さらに部分問題をより小さな部分問題へと分解し、基本ケースに達したところで停止します(基本ケースの解は既知です)。
前述の総和関数を例に、問題を \(f(n) = 1 + 2 + \dots + n\) とします。
- 反復:ループ内で総和の過程を模擬し、\(1\) から \(n\) まで走査して、各反復で加算を行えば \(f(n)\) を求められます。
- 再帰:問題を部分問題 \(f(n) = n + f(n-1)\) に分解し、これを再帰的に分解し続け、基本ケース \(f(1) = 1\) に達したところで終了します。
1. 呼び出しスタック¶
再帰関数が自分自身を呼び出すたびに、システムは新たに開始された関数のためにメモリを割り当て、局所変数、呼び出し先アドレス、その他の情報を保存します。これにより 2 つの結果が生じます。
- 関数のコンテキストデータは「スタックフレーム領域」と呼ばれるメモリ領域に保存され、関数が戻るまで解放されません。したがって、再帰は通常、反復より多くのメモリ空間を消費します。
- 再帰による関数呼び出しには追加のオーバーヘッドが発生します。そのため再帰は通常、ループより時間効率が低くなります。
次の図のように、終了条件が発動する前には、まだ戻っていない再帰関数が同時に \(n\) 個存在し、再帰の深さは \(n\) になります。

図 2-4 再帰呼び出しの深さ
実際には、プログラミング言語が許容する再帰の深さには通常上限があり、深すぎる再帰はスタックオーバーフローを引き起こす可能性があります。
2. 末尾再帰¶
興味深いことに、関数が返る直前の最後の処理で再帰呼び出しを行う場合、その関数はコンパイラやインタプリタによって最適化され、空間効率が反復と同程度になることがあります。これを末尾再帰(tail recursion)と呼びます。
- 通常の再帰:関数が 1 つ上の階層の関数へ戻った後も、引き続きコードを実行する必要があるため、システムは 1 つ上の呼び出しのコンテキストを保存しておく必要があります。
- 末尾再帰:再帰呼び出しが関数の返却前の最後の操作であるため、1 つ上の階層へ戻った後に他の処理を続ける必要がなく、システムは 1 つ上の関数のコンテキストを保存する必要がありません。
\(1 + 2 + \dots + n\) の計算を例にすると、結果変数 res を関数の引数にすることで、末尾再帰を実現できます。
コードの可視化
末尾再帰の実行過程を次の図に示します。通常の再帰と末尾再帰を比べると、加算処理が実行されるタイミングが異なります。
- 通常の再帰:加算処理は復帰の過程で実行され、各層が戻るたびにもう一度加算を行います。
- 末尾再帰:加算処理は再帰呼び出しの過程で実行され、復帰の過程では各層が戻るだけで済みます。

図 2-5 末尾再帰の過程
Tip
多くのコンパイラやインタプリタは末尾再帰最適化をサポートしていない点に注意してください。たとえば、Python はデフォルトで末尾再帰最適化をサポートしていないため、関数が末尾再帰の形であっても、スタックオーバーフローが発生する可能性があります。
3. 再帰木¶
「分割統治」に関連するアルゴリズム問題を扱う際、再帰は反復よりも発想が直感的で、コードも読みやすいことがよくあります。「フィボナッチ数列」を例に見てみましょう。
Question
フィボナッチ数列 \(0, 1, 1, 2, 3, 5, 8, 13, \dots\) が与えられたとき、この数列の第 \(n\) 項を求めてください。
フィボナッチ数列の第 \(n\) 項を \(f(n)\) とすると、次の 2 つが容易に分かります。
- 数列の最初の 2 項は \(f(1) = 0\) と \(f(2) = 1\) です。
- 数列中の各項は直前の 2 項の和であり、すなわち \(f(n) = f(n - 1) + f(n - 2)\) です。
漸化式に従って再帰呼び出しを行い、最初の 2 項を終了条件とすれば、再帰コードを書けます。fib(n) を呼び出すことでフィボナッチ数列の第 \(n\) 項を得られます。
コードの可視化
上のコードを見ると、関数内で 2 回の再帰呼び出しを行っています。これは 1 回の呼び出しから 2 つの呼び出し分岐が生じることを意味します。次の図のように、この再帰呼び出しを繰り返していくと、最終的に深さ \(n\) の再帰木(recursion tree)が生成されます。
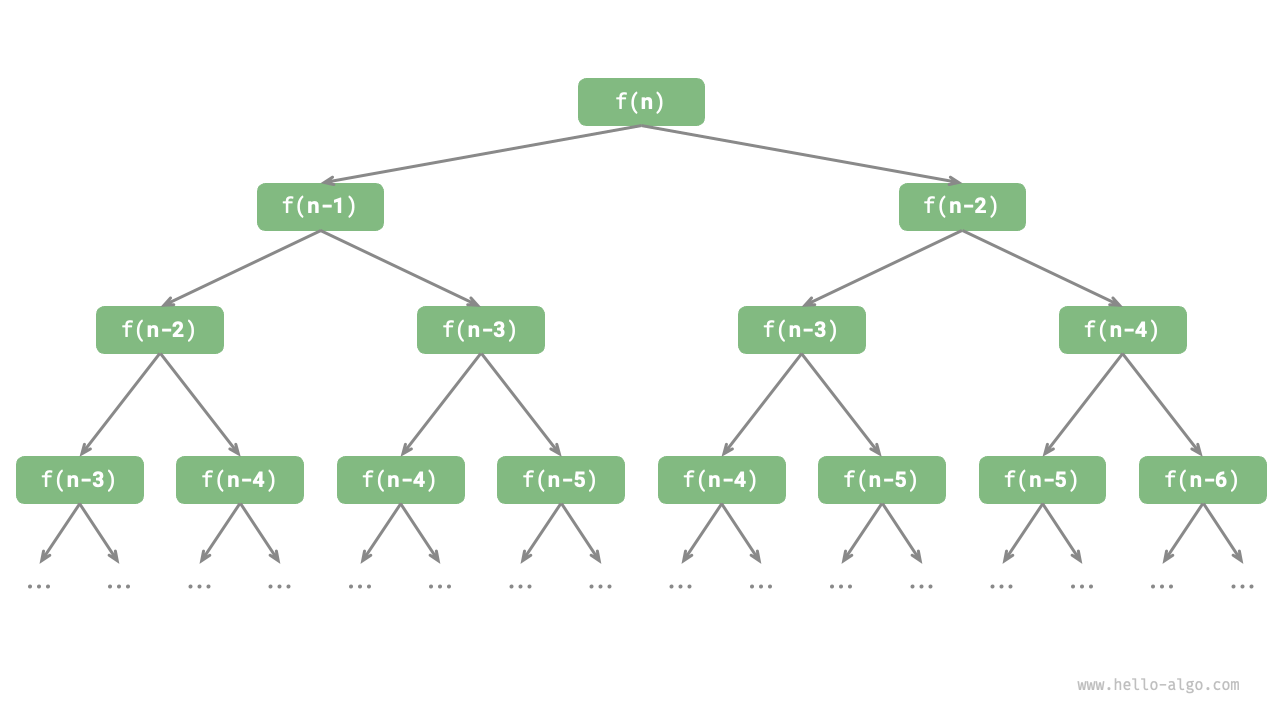
図 2-6 フィボナッチ数列の再帰木
本質的に見ると、再帰は「問題をより小さな部分問題へ分解する」という思考パラダイムを体現しており、この分割統治の戦略は非常に重要です。
- アルゴリズムの観点では、探索、ソート、バックトラッキング、分割統治、動的計画法など、多くの重要な戦略が直接または間接にこの考え方を用いています。
- データ構造の観点では、再帰は連結リスト、木、グラフに関する問題の処理に本質的に適しており、これらは分割統治の考え方で分析しやすいからです。
2.2.3 両者の比較¶
以上をまとめると、次の表のように、反復と再帰は実装、性能、適用性の面で違いがあります。
表 2-1 反復と再帰の特徴の比較
| 反復 | 再帰 | |
|---|---|---|
| 実装方法 | ループ構造 | 関数が自分自身を呼び出す |
| 時間効率 | 通常は効率が高く、関数呼び出しの負荷がない | 関数呼び出しのたびにオーバーヘッドが発生する |
| メモリ使用 | 通常は固定サイズのメモリ空間を使う | 関数呼び出しの蓄積により大量のスタックフレーム領域を使う可能性がある |
| 適用対象 | 単純な反復処理に適し、コードが直感的で読みやすい | 木、グラフ、分割統治、バックトラッキングなどの部分問題分解に適し、コード構造が簡潔で明快 |
Tip
以下の内容が難しいと感じる場合は、「スタック」の章を読み終えた後に改めて復習してください。
では、反復と再帰にはどのような内在的な関係があるのでしょうか。前述の再帰関数を例にすると、加算処理は再帰の復帰段階で行われます。これは、最初に呼び出された関数が実際には最後に加算を完了することを意味しており、この動作の仕組みはスタックの「後入れ先出し」の原則とよく似ています。
実際、「呼び出しスタック」や「スタックフレーム領域」といった再帰の用語自体が、再帰とスタックの密接な関係を示唆しています。
- 再帰呼び出し:関数が呼び出されると、システムは「呼び出しスタック」上にその関数のための新しいスタックフレームを割り当て、局所変数、引数、返却先アドレスなどのデータを保存します。
- 復帰:関数の実行が完了して戻ると、対応するスタックフレームは「呼び出しスタック」から取り除かれ、前の関数の実行環境が復元されます。
したがって、明示的なスタックを使って呼び出しスタックの振る舞いを模擬することができ、その結果として再帰を反復形式へ変換できます。
/* 反復で再帰を模擬する */
int forLoopRecur(int n) {
// 明示的なスタックを使ってシステムコールスタックを模擬する
stack<int> stack;
int res = 0;
// 再帰:再帰呼び出し
for (int i = n; i > 0; i--) {
// 「スタックへのプッシュ」で「再帰」を模擬する
stack.push(i);
}
// 帰りがけ:結果を返す
while (!stack.empty()) {
// 「スタックから取り出す操作」で「帰り」をシミュレート
res += stack.top();
stack.pop();
}
// res = 1+2+3+...+n
return res;
}
/* 反復で再帰を模擬する */
int forLoopRecur(int n) {
// 明示的なスタックを使ってシステムコールスタックを模擬する
Stack<Integer> stack = new Stack<>();
int res = 0;
// 再帰:再帰呼び出し
for (int i = n; i > 0; i--) {
// 「スタックへのプッシュ」で「再帰」を模擬する
stack.push(i);
}
// 帰りがけ:結果を返す
while (!stack.isEmpty()) {
// 「スタックから取り出す操作」で「帰り」をシミュレート
res += stack.pop();
}
// res = 1+2+3+...+n
return res;
}
/* 反復で再帰を模擬する */
int ForLoopRecur(int n) {
// 明示的なスタックを使ってシステムコールスタックを模擬する
Stack<int> stack = new();
int res = 0;
// 再帰:再帰呼び出し
for (int i = n; i > 0; i--) {
// 「スタックへのプッシュ」で「再帰」を模擬する
stack.Push(i);
}
// 帰りがけ:結果を返す
while (stack.Count > 0) {
// 「スタックから取り出す操作」で「帰り」をシミュレート
res += stack.Pop();
}
// res = 1+2+3+...+n
return res;
}
/* 反復で再帰を模擬する */
func forLoopRecur(n int) int {
// 明示的なスタックを使ってシステムコールスタックを模擬する
stack := list.New()
res := 0
// 再帰:再帰呼び出し
for i := n; i > 0; i-- {
// 「スタックへのプッシュ」で「再帰」を模擬する
stack.PushBack(i)
}
// 帰りがけ:結果を返す
for stack.Len() != 0 {
// 「スタックから取り出す操作」で「帰り」をシミュレート
res += stack.Back().Value.(int)
stack.Remove(stack.Back())
}
// res = 1+2+3+...+n
return res
}
/* 反復で再帰を模擬する */
func forLoopRecur(n: Int) -> Int {
// 明示的なスタックを使ってシステムコールスタックを模擬する
var stack: [Int] = []
var res = 0
// 再帰:再帰呼び出し
for i in (1 ... n).reversed() {
// 「スタックへのプッシュ」で「再帰」を模擬する
stack.append(i)
}
// 帰りがけ:結果を返す
while !stack.isEmpty {
// 「スタックから取り出す操作」で「帰り」をシミュレート
res += stack.removeLast()
}
// res = 1+2+3+...+n
return res
}
/* 反復で再帰を模擬する */
function forLoopRecur(n) {
// 明示的なスタックを使ってシステムコールスタックを模擬する
const stack = [];
let res = 0;
// 再帰:再帰呼び出し
for (let i = n; i > 0; i--) {
// 「スタックへのプッシュ」で「再帰」を模擬する
stack.push(i);
}
// 帰りがけ:結果を返す
while (stack.length) {
// 「スタックから取り出す操作」で「帰り」をシミュレート
res += stack.pop();
}
// res = 1+2+3+...+n
return res;
}
/* 反復で再帰を模擬する */
function forLoopRecur(n: number): number {
// 明示的なスタックを使ってシステムコールスタックを模擬する
const stack: number[] = [];
let res: number = 0;
// 再帰:再帰呼び出し
for (let i = n; i > 0; i--) {
// 「スタックへのプッシュ」で「再帰」を模擬する
stack.push(i);
}
// 帰りがけ:結果を返す
while (stack.length) {
// 「スタックから取り出す操作」で「帰り」をシミュレート
res += stack.pop();
}
// res = 1+2+3+...+n
return res;
}
/* 反復で再帰を模擬する */
int forLoopRecur(int n) {
// 明示的なスタックを使ってシステムコールスタックを模擬する
List<int> stack = [];
int res = 0;
// 再帰:再帰呼び出し
for (int i = n; i > 0; i--) {
// 「スタックへのプッシュ」で「再帰」を模擬する
stack.add(i);
}
// 帰りがけ:結果を返す
while (!stack.isEmpty) {
// 「スタックから取り出す操作」で「帰り」をシミュレート
res += stack.removeLast();
}
// res = 1+2+3+...+n
return res;
}
/* 反復で再帰を模擬する */
fn for_loop_recur(n: i32) -> i32 {
// 明示的なスタックを使ってシステムコールスタックを模擬する
let mut stack = Vec::new();
let mut res = 0;
// 再帰:再帰呼び出し
for i in (1..=n).rev() {
// 「スタックへのプッシュ」で「再帰」を模擬する
stack.push(i);
}
// 帰りがけ:結果を返す
while !stack.is_empty() {
// 「スタックから取り出す操作」で「帰り」をシミュレート
res += stack.pop().unwrap();
}
// res = 1+2+3+...+n
res
}
/* 反復で再帰を模擬する */
int forLoopRecur(int n) {
int stack[1000]; // 大きな配列を使ってスタックを実装する
int top = -1; // スタックトップのインデックス
int res = 0;
// 再帰:再帰呼び出し
for (int i = n; i > 0; i--) {
// 「スタックへのプッシュ」で「再帰」を模擬する
stack[1 + top++] = i;
}
// 帰りがけ:結果を返す
while (top >= 0) {
// 「スタックから取り出す操作」で「帰り」をシミュレート
res += stack[top--];
}
// res = 1+2+3+...+n
return res;
}
/* 反復で再帰を模擬する */
fun forLoopRecur(n: Int): Int {
// 明示的なスタックを使ってシステムコールスタックを模擬する
val stack = Stack<Int>()
var res = 0
// 再帰: 再帰呼び出し
for (i in n downTo 0) {
// 「スタックへのプッシュ」で「再帰」を模擬する
stack.push(i)
}
// 戻る: 結果を返す
while (stack.isNotEmpty()) {
// 「スタックから取り出す操作」で「帰り」をシミュレート
res += stack.pop()
}
// res = 1+2+3+...+n
return res
}
コードの可視化
上のコードを見ると、再帰を反復へ変換すると、コードはより複雑になります。反復と再帰は多くの場合に相互変換できますが、常にそうする価値があるとは限りません。理由は次の 2 点です。
- 変換後のコードは理解しにくくなり、可読性が下がる可能性があります。
- 複雑な問題によっては、システムの呼び出しスタックの振る舞いを模擬すること自体が非常に難しい場合があります。
要するに、反復を選ぶか再帰を選ぶかは、対象となる問題の性質によって決まります。実際のプログラミングでは、両者の長所と短所を見極め、状況に応じて適切な方法を選ぶことが重要です。