2.3 Временная сложность¶
Время выполнения действительно может наглядно и точно отражать эффективность алгоритма. Но если мы захотим точно оценить время работы некоторого фрагмента кода, то столкнемся со следующими шагами.
- Определить платформу выполнения, включая конфигурацию оборудования, язык программирования, системную среду и т.д., поскольку все эти факторы влияют на эффективность выполнения кода.
- Оценить время выполнения различных вычислительных операций, например операция сложения
+требует 1 нс , операция умножения*требует 10 нс , операция выводаprint()требует 5 нс и т.д. - Подсчитать все вычислительные операции в коде и суммировать время выполнения всех операций, чтобы получить общее время работы.
Например, в следующем коде размер входных данных равен \(n\) :
Согласно приведенному выше методу, время работы алгоритма равно \((6n + 12)\) нс :
Но на практике подсчитывать реальное время выполнения алгоритма и неразумно, и нереалистично. Во-первых, мы не хотим привязывать оценку времени к конкретной платформе, потому что алгоритм должен запускаться на самых разных платформах. Во-вторых, нам трудно определить время выполнения каждого типа операций, а это делает точную оценку крайне затруднительной.
2.3.1 Подсчет тенденции роста времени¶
Анализ временной сложности оценивает не само время выполнения алгоритма, а тенденцию роста этого времени по мере увеличения объема данных.
Понятие «тенденции роста времени» выглядит довольно абстрактным, поэтому разберем его на примере. Предположим, размер входных данных равен \(n\) , и даны три алгоритма A , B и C :
// Временная сложность алгоритма A: постоянная
void algorithm_A(int n) {
cout << 0 << endl;
}
// Временная сложность алгоритма B: линейная
void algorithm_B(int n) {
for (int i = 0; i < n; i++) {
cout << 0 << endl;
}
}
// Временная сложность алгоритма C: постоянная
void algorithm_C(int n) {
for (int i = 0; i < 1000000; i++) {
cout << 0 << endl;
}
}
// Временная сложность алгоритма A: постоянная
void algorithm_A(int n) {
System.out.println(0);
}
// Временная сложность алгоритма B: линейная
void algorithm_B(int n) {
for (int i = 0; i < n; i++) {
System.out.println(0);
}
}
// Временная сложность алгоритма C: постоянная
void algorithm_C(int n) {
for (int i = 0; i < 1000000; i++) {
System.out.println(0);
}
}
// Временная сложность алгоритма A: постоянная
void AlgorithmA(int n) {
Console.WriteLine(0);
}
// Временная сложность алгоритма B: линейная
void AlgorithmB(int n) {
for (int i = 0; i < n; i++) {
Console.WriteLine(0);
}
}
// Временная сложность алгоритма C: постоянная
void AlgorithmC(int n) {
for (int i = 0; i < 1000000; i++) {
Console.WriteLine(0);
}
}
// Временная сложность алгоритма A: постоянная
func algorithm_A(n int) {
fmt.Println(0)
}
// Временная сложность алгоритма B: линейная
func algorithm_B(n int) {
for i := 0; i < n; i++ {
fmt.Println(0)
}
}
// Временная сложность алгоритма C: постоянная
func algorithm_C(n int) {
for i := 0; i < 1000000; i++ {
fmt.Println(0)
}
}
// Временная сложность алгоритма A: постоянная
function algorithm_A(n) {
console.log(0);
}
// Временная сложность алгоритма B: линейная
function algorithm_B(n) {
for (let i = 0; i < n; i++) {
console.log(0);
}
}
// Временная сложность алгоритма C: постоянная
function algorithm_C(n) {
for (let i = 0; i < 1000000; i++) {
console.log(0);
}
}
// Временная сложность алгоритма A: постоянная
function algorithm_A(n: number): void {
console.log(0);
}
// Временная сложность алгоритма B: линейная
function algorithm_B(n: number): void {
for (let i = 0; i < n; i++) {
console.log(0);
}
}
// Временная сложность алгоритма C: постоянная
function algorithm_C(n: number): void {
for (let i = 0; i < 1000000; i++) {
console.log(0);
}
}
// Временная сложность алгоритма A: постоянная
void algorithmA(int n) {
print(0);
}
// Временная сложность алгоритма B: линейная
void algorithmB(int n) {
for (int i = 0; i < n; i++) {
print(0);
}
}
// Временная сложность алгоритма C: постоянная
void algorithmC(int n) {
for (int i = 0; i < 1000000; i++) {
print(0);
}
}
// Временная сложность алгоритма A: постоянная
fn algorithm_A(n: i32) {
println!("{}", 0);
}
// Временная сложность алгоритма B: линейная
fn algorithm_B(n: i32) {
for _ in 0..n {
println!("{}", 0);
}
}
// Временная сложность алгоритма C: постоянная
fn algorithm_C(n: i32) {
for _ in 0..1000000 {
println!("{}", 0);
}
}
// Временная сложность алгоритма A: постоянная
void algorithm_A(int n) {
printf("%d", 0);
}
// Временная сложность алгоритма B: линейная
void algorithm_B(int n) {
for (int i = 0; i < n; i++) {
printf("%d", 0);
}
}
// Временная сложность алгоритма C: постоянная
void algorithm_C(int n) {
for (int i = 0; i < 1000000; i++) {
printf("%d", 0);
}
}
// Временная сложность алгоритма A: постоянная
fun algoritm_A(n: Int) {
println(0)
}
// Временная сложность алгоритма B: линейная
fun algorithm_B(n: Int) {
for (i in 0..<n){
println(0)
}
}
// Временная сложность алгоритма C: постоянная
fun algorithm_C(n: Int) {
for (i in 0..<1000000) {
println(0)
}
}
На рисунке 2-7 показаны временные сложности трех приведенных выше функций.
- У алгоритма
Aесть только одна операция вывода, и время его работы не растет с увеличением \(n\) . Такую временную сложность называют постоянной. - В алгоритме
Bоперация вывода выполняется в цикле \(n\) раз, поэтому время работы растет линейно по мере увеличения \(n\) . Такая временная сложность называется линейной. - В алгоритме
Cоперация вывода выполняется \(1000000\) раз. Хотя время работы велико, оно не зависит от размера входных данных \(n\) . Поэтому временная сложностьCтакая же, как уA, и тоже является постоянной.
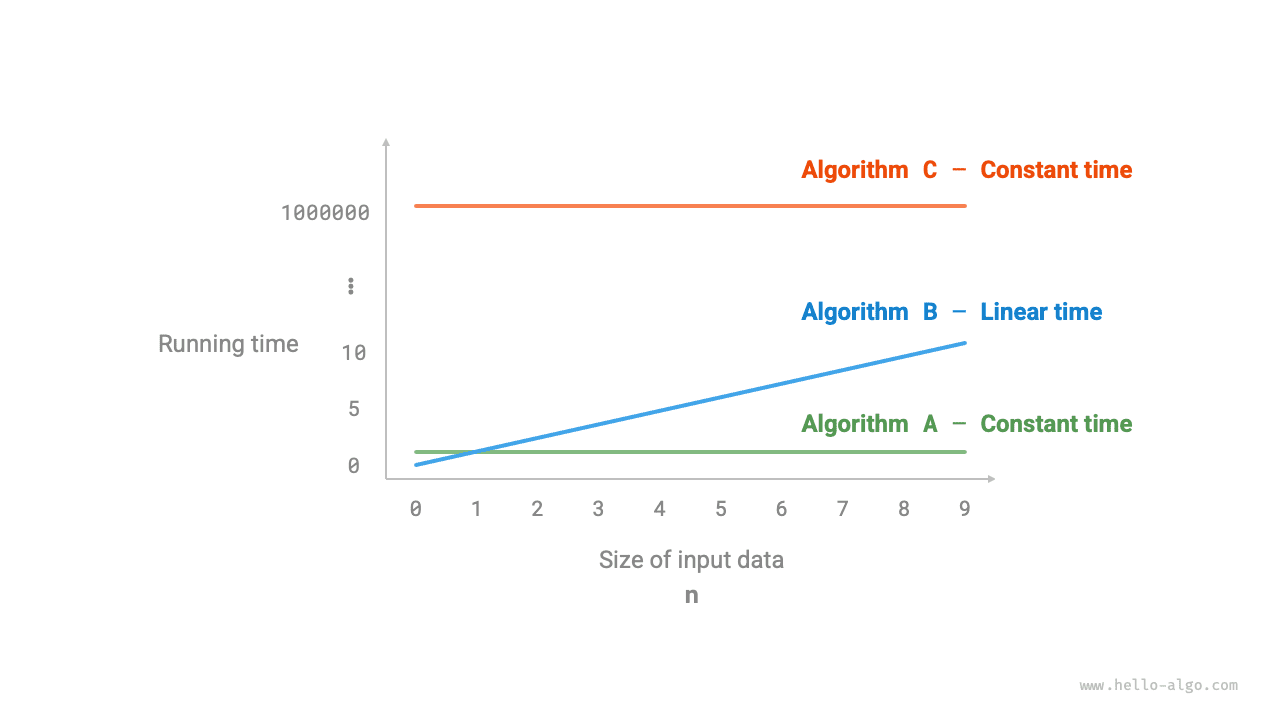
Рисунок 2-7 Тенденции роста времени для алгоритмов A, B и C
Какие особенности имеет анализ временной сложности по сравнению с непосредственным измерением времени работы алгоритма?
- Временная сложность позволяет эффективно оценивать эффективность алгоритма. Например, время работы алгоритма
Bрастет линейно: при \(n > 1\) он медленнее алгоритмаA, а при \(n > 1000000\) медленнее алгоритмаC. Если размер входных данных достаточно велик, алгоритм с постоянной сложностью обязательно лучше алгоритма с линейной сложностью. В этом и состоит смысл тенденции роста времени. - Метод вывода временной сложности проще. Платформа выполнения и тип вычислительных операций не влияют на тенденцию роста времени работы алгоритма. Поэтому в анализе временной сложности можно считать время выполнения всех вычислительных операций одинаковым единичным временем и тем самым упростить подсчет времени выполнения до подсчета количества операций.
- У временной сложности есть и определенные ограничения. Например, хотя временная сложность алгоритмов
AиCодинакова, их реальное время выполнения сильно различается. Точно так же, хотя временная сложностьBвыше, чем уC, при малых \(n\) алгоритмBочевидно лучшеC. Несмотря на эти ограничения, анализ сложности все равно остается самым эффективным и самым распространенным способом оценки алгоритмов.
2.3.2 Асимптотическая верхняя граница функции¶
Для функции с входным размером \(n\) :
Пусть количество операций алгоритма является функцией от размера входных данных \(n\) и обозначается как \(T(n)\). Тогда для приведенной выше функции число операций равно:
\(T(n)\) - линейная функция, а это означает, что тенденция роста времени работы линейна, следовательно, временная сложность здесь тоже линейна.
Линейную временную сложность записывают как \(O(n)\). Этот математический символ называется нотацией Big \(O\) (big-\(O\) notation) и обозначает асимптотическую верхнюю границу (asymptotic upper bound) функции \(T(n)\) .
Иными словами, анализ временной сложности сводится к определению асимптотической верхней границы числа операций \(T(n)\), и у этого понятия есть строгое математическое определение.
Асимптотическая верхняя граница функции
Если существуют положительное действительное число \(c\) и действительное число \(n_0\) , такие что для всех \(n > n_0\) выполняется \(T(n) \leq c \cdot f(n)\) , то можно считать, что \(f(n)\) задает асимптотическую верхнюю границу для \(T(n)\). Это записывается как \(T(n) = O(f(n))\) .
Как показано на рисунке 2-8, вычислить асимптотическую верхнюю границу - значит найти такую функцию \(f(n)\) , что при стремлении \(n\) к бесконечности функции \(T(n)\) и \(f(n)\) имеют один и тот же порядок роста и отличаются только постоянным коэффициентом \(c\).
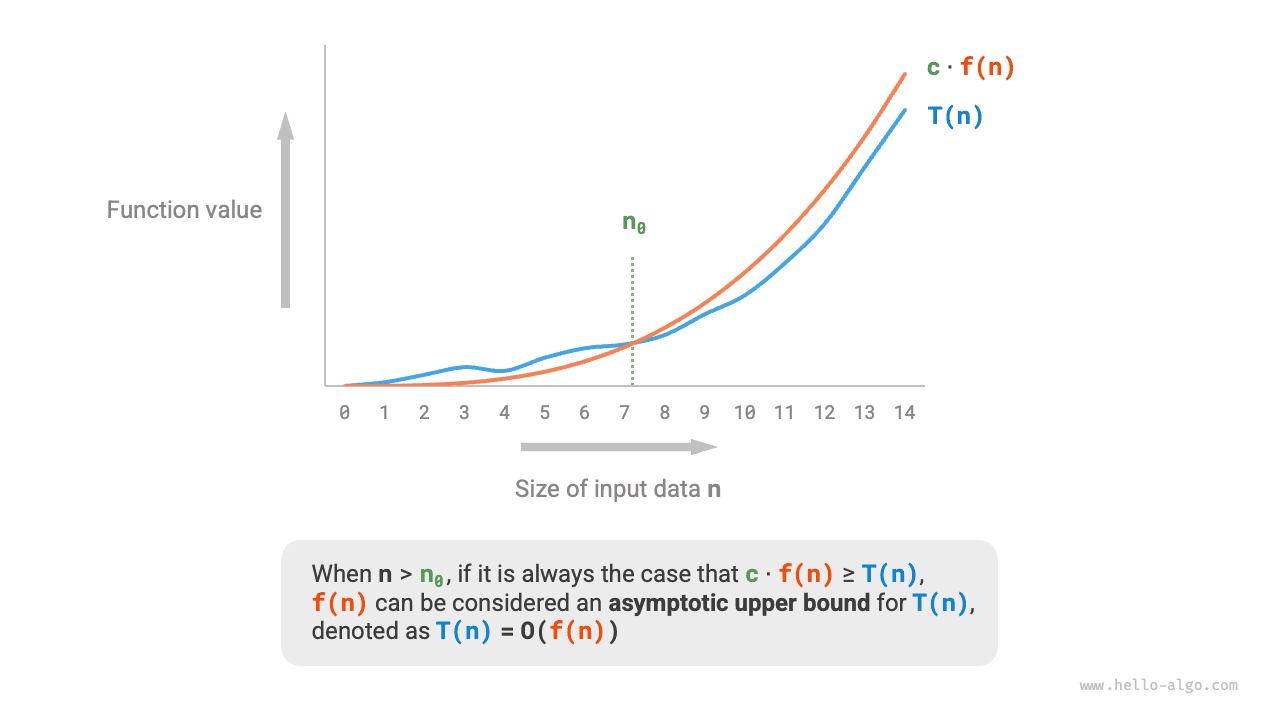
Рисунок 2-8 Асимптотическая верхняя граница функции
2.3.3 Метод вывода¶
Математическое определение асимптотической верхней границы выглядит довольно формально, и если оно пока не до конца понятно, переживать не стоит. Сначала можно освоить сам метод вывода, а в процессе дальнейшей практики постепенно почувствовать его математический смысл.
Согласно определению, после того как мы определили \(f(n)\) , можно получить временную сложность \(O(f(n))\) . Но как определить саму асимптотическую верхнюю границу \(f(n)\) ? В целом процесс состоит из двух шагов: сначала подсчитать количество операций, затем определить асимптотическую верхнюю границу.
1. Шаг 1: подсчет количества операций¶
Для кода это можно делать построчно сверху вниз. Однако, поскольку в выражении \(c \cdot f(n)\) постоянный коэффициент \(c\) может быть сколь угодно большим, различные коэффициенты и постоянные члены в числе операций \(T(n)\) можно игнорировать. Исходя из этого принципа, можно сформулировать следующие упрощающие приемы подсчета.
- Игнорировать константы в \(T(n)\). Они не зависят от \(n\) , а значит не влияют на временную сложность.
- Опускать все коэффициенты. Например, циклы на \(2n\) раз или \(5n + 1\) раз можно упростить до \(n\) раз, потому что коэффициент перед \(n\) не влияет на временную сложность.
- При вложенных циклах использовать умножение. Общее число операций равно произведению числа операций внешнего и внутреннего циклов. При этом для каждого уровня цикла по-прежнему можно применять приемы из пунктов
1.и2..
Для заданной функции мы можем использовать перечисленные выше приемы и подсчитать число операций:
Следующая формула показывает результаты подсчета до и после использования перечисленных выше приемов. В обоих случаях выводимая временная сложность равна \(O(n^2)\) .
2. Шаг 2: определение асимптотической верхней границы¶
**Временная сложность определяется старшим по степени членом в \(T(n)\) **. Это связано с тем, что при стремлении \(n\) к бесконечности именно старший член начинает доминировать, а влиянием остальных членов можно пренебречь.
В таблице 2-2 приведены несколько примеров. Некоторые значения специально сделаны преувеличенными, чтобы подчеркнуть вывод: коэффициент не способен изменить порядок. Когда \(n\) стремится к бесконечности, эти константы становятся несущественными.
Таблица 2-2 Временная сложность, соответствующая разному количеству операций
| Число операций \(T(n)\) | Временная сложность \(O(f(n))\) |
|---|---|
| \(100000\) | \(O(1)\) |
| \(3n + 2\) | \(O(n)\) |
| \(2n^2 + 3n + 2\) | \(O(n^2)\) |
| \(n^3 + 10000n^2\) | \(O(n^3)\) |
| \(2^n + 10000n^{10000}\) | \(O(2^n)\) |
2.3.4 Распространенные типы¶
Пусть размер входных данных равен \(n\). Распространенные типы временной сложности показаны на рисунке 2-9 в порядке от меньшей к большей.
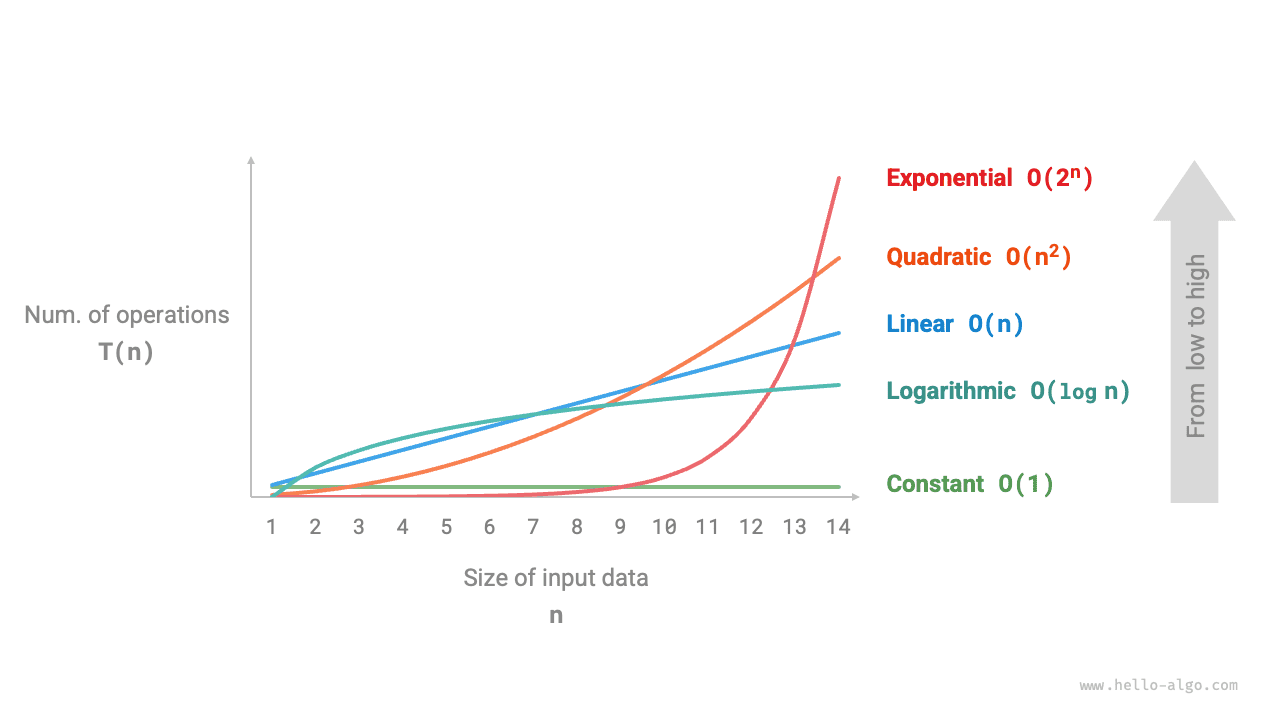
Рисунок 2-9 Распространенные типы временной сложности
1. Постоянная сложность \(O(1)\)¶
Число операций при постоянной сложности не зависит от размера входных данных \(n\) , то есть не изменяется вместе с изменением \(n\) .
В следующей функции, хотя число операций size может быть большим, оно не зависит от размера входных данных \(n\) , поэтому временная сложность по-прежнему равна \(O(1)\) :
Визуализация кода
2. Линейная сложность \(O(n)\)¶
Линейная сложность характеризуется тем, что число операций растет линейно относительно размера входных данных \(n\) . Линейная сложность обычно встречается в одноуровневых циклах:
Визуализация кода
Операции обхода массива и обхода связного списка имеют временную сложность \(O(n)\) , где \(n\) - длина массива или списка:
Визуализация кода
Стоит отметить, что размер входных данных \(n\) нужно определять конкретно в зависимости от типа входа. Например, в первом примере переменная \(n\) сама является размером входных данных. Во втором примере размером данных служит длина массива.
3. Квадратичная сложность \(O(n^2)\)¶
Квадратичная сложность характеризуется тем, что число операций растет квадратично относительно размера входных данных \(n\) . Квадратичная сложность обычно встречается во вложенных циклах: временная сложность внешнего и внутреннего циклов равна \(O(n)\) , поэтому общая временная сложность составляет \(O(n^2)\) :
Визуализация кода
На рисунке 2-10 сравниваются три временные сложности: постоянная, линейная и квадратичная.
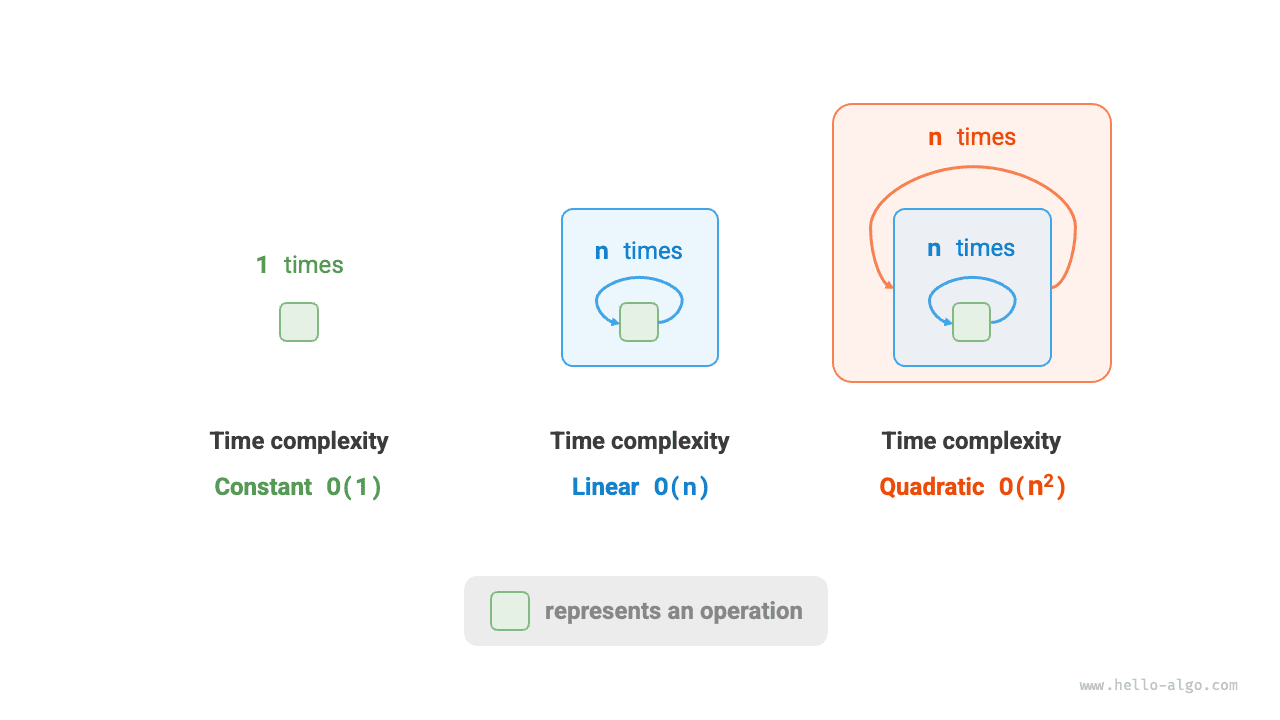
Рисунок 2-10 Постоянная, линейная и квадратичная временная сложность
Возьмем в качестве примера пузырьковую сортировку: внешний цикл выполняется \(n - 1\) раз, внутренний цикл выполняется \(n-1\) , \(n-2\) , \(\dots\) , \(2\) , \(1\) раз, в среднем это \(n / 2\) раз, поэтому временная сложность равна \(O((n - 1)n / 2) = O(n^2)\) :
def bubble_sort(nums: list[int]) -> int:
"""Квадратичная сложность (пузырьковая сортировка)"""
count = 0 # Счетчик
# Внешний цикл: неотсортированный диапазон [0, i]
for i in range(len(nums) - 1, 0, -1):
# Внутренний цикл: переместить максимальный элемент неотсортированного диапазона [0, i] в его правый конец
for j in range(i):
if nums[j] > nums[j + 1]:
# Поменять местами nums[j] и nums[j + 1]
tmp: int = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 # Обмен элементов включает 3 элементарные операции
return count
/* Квадратичная сложность (пузырьковая сортировка) */
int bubbleSort(vector<int> &nums) {
int count = 0; // Счетчик
// Внешний цикл: неотсортированный диапазон [0, i]
for (int i = nums.size() - 1; i > 0; i--) {
// Внутренний цикл: переместить максимальный элемент неотсортированного диапазона [0, i] в его правый конец
for (int j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// Поменять местами nums[j] и nums[j + 1]
int tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // Обмен элементов включает 3 элементарные операции
}
}
}
return count;
}
/* Квадратичная сложность (пузырьковая сортировка) */
int bubbleSort(int[] nums) {
int count = 0; // Счетчик
// Внешний цикл: неотсортированный диапазон [0, i]
for (int i = nums.length - 1; i > 0; i--) {
// Внутренний цикл: переместить максимальный элемент неотсортированного диапазона [0, i] в его правый конец
for (int j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// Поменять местами nums[j] и nums[j + 1]
int tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // Обмен элементов включает 3 элементарные операции
}
}
}
return count;
}
/* Квадратичная сложность (пузырьковая сортировка) */
int BubbleSort(int[] nums) {
int count = 0; // Счетчик
// Внешний цикл: неотсортированный диапазон [0, i]
for (int i = nums.Length - 1; i > 0; i--) {
// Внутренний цикл: переместить максимальный элемент неотсортированного диапазона [0, i] в его правый конец
for (int j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// Поменять местами nums[j] и nums[j + 1]
(nums[j + 1], nums[j]) = (nums[j], nums[j + 1]);
count += 3; // Обмен элементов включает 3 элементарные операции
}
}
}
return count;
}
/* Квадратичная сложность (пузырьковая сортировка) */
func bubbleSort(nums []int) int {
count := 0 // Счетчик
// Внешний цикл: неотсортированный диапазон [0, i]
for i := len(nums) - 1; i > 0; i-- {
// Внутренний цикл: переместить максимальный элемент неотсортированного диапазона [0, i] в его правый конец
for j := 0; j < i; j++ {
if nums[j] > nums[j+1] {
// Поменять местами nums[j] и nums[j + 1]
tmp := nums[j]
nums[j] = nums[j+1]
nums[j+1] = tmp
count += 3 // Обмен элементов включает 3 элементарные операции
}
}
}
return count
}
/* Квадратичная сложность (пузырьковая сортировка) */
func bubbleSort(nums: inout [Int]) -> Int {
var count = 0 // Счетчик
// Внешний цикл: неотсортированный диапазон [0, i]
for i in nums.indices.dropFirst().reversed() {
// Внутренний цикл: переместить максимальный элемент неотсортированного диапазона [0, i] в его правый конец
for j in 0 ..< i {
if nums[j] > nums[j + 1] {
// Поменять местами nums[j] и nums[j + 1]
let tmp = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 // Обмен элементов включает 3 элементарные операции
}
}
}
return count
}
/* Квадратичная сложность (пузырьковая сортировка) */
function bubbleSort(nums) {
let count = 0; // Счетчик
// Внешний цикл: неотсортированный диапазон [0, i]
for (let i = nums.length - 1; i > 0; i--) {
// Внутренний цикл: переместить максимальный элемент неотсортированного диапазона [0, i] в его правый конец
for (let j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// Поменять местами nums[j] и nums[j + 1]
let tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // Обмен элементов включает 3 элементарные операции
}
}
}
return count;
}
/* Квадратичная сложность (пузырьковая сортировка) */
function bubbleSort(nums: number[]): number {
let count = 0; // Счетчик
// Внешний цикл: неотсортированный диапазон [0, i]
for (let i = nums.length - 1; i > 0; i--) {
// Внутренний цикл: переместить максимальный элемент неотсортированного диапазона [0, i] в его правый конец
for (let j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// Поменять местами nums[j] и nums[j + 1]
let tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // Обмен элементов включает 3 элементарные операции
}
}
}
return count;
}
/* Квадратичная сложность (пузырьковая сортировка) */
int bubbleSort(List<int> nums) {
int count = 0; // Счетчик
// Внешний цикл: неотсортированный диапазон [0, i]
for (var i = nums.length - 1; i > 0; i--) {
// Внутренний цикл: переместить максимальный элемент неотсортированного диапазона [0, i] в его правый конец
for (var j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// Поменять местами nums[j] и nums[j + 1]
int tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // Обмен элементов включает 3 элементарные операции
}
}
}
return count;
}
/* Квадратичная сложность (пузырьковая сортировка) */
fn bubble_sort(nums: &mut [i32]) -> i32 {
let mut count = 0; // Счетчик
// Внешний цикл: неотсортированный диапазон [0, i]
for i in (1..nums.len()).rev() {
// Внутренний цикл: переместить максимальный элемент неотсортированного диапазона [0, i] в его правый конец
for j in 0..i {
if nums[j] > nums[j + 1] {
// Поменять местами nums[j] и nums[j + 1]
let tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // Обмен элементов включает 3 элементарные операции
}
}
}
count
}
/* Квадратичная сложность (пузырьковая сортировка) */
int bubbleSort(int *nums, int n) {
int count = 0; // Счетчик
// Внешний цикл: неотсортированный диапазон [0, i]
for (int i = n - 1; i > 0; i--) {
// Внутренний цикл: переместить максимальный элемент неотсортированного диапазона [0, i] в его правый конец
for (int j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// Поменять местами nums[j] и nums[j + 1]
int tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // Обмен элементов включает 3 элементарные операции
}
}
}
return count;
}
/* Квадратичная сложность (пузырьковая сортировка) */
fun bubbleSort(nums: IntArray): Int {
var count = 0 // Счетчик
// Внешний цикл: неотсортированный диапазон [0, i]
for (i in nums.size - 1 downTo 1) {
// Внутренний цикл: переместить максимальный элемент неотсортированного диапазона [0, i] в его правый конец
for (j in 0..<i) {
if (nums[j] > nums[j + 1]) {
// Поменять местами nums[j] и nums[j + 1]
val temp = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = temp
count += 3 // Обмен элементов включает 3 элементарные операции
}
}
}
return count
}
### Квадратичная сложность ###
def quadratic(n)
count = 0
# Число итераций квадратично зависит от размера данных n
for i in 0...n
for j in 0...n
count += 1
end
end
count
end
# ## Квадратичная сложность (пузырьковая сортировка) ###
def bubble_sort(nums)
count = 0 # Счетчик
# Внешний цикл: неотсортированный диапазон [0, i]
for i in (nums.length - 1).downto(0)
# Внутренний цикл: переместить максимальный элемент неотсортированного диапазона [0, i] в его правый конец
for j in 0...i
if nums[j] > nums[j + 1]
# Поменять местами nums[j] и nums[j + 1]
tmp = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 # Обмен элементов включает 3 элементарные операции
end
end
end
count
end
Визуализация кода
4. Экспоненциальная сложность \(O(2^n)\)¶
Типичный пример экспоненциального роста в биологии - деление клеток: в начальном состоянии есть одна клетка, после одного деления их становится 2, после двух делений - 4 и так далее. После \(n\) раундов деления клеток становится \(2^n\) .
На рисунке 2-11 и в следующем коде моделируется процесс деления клеток. Временная сложность равна \(O(2^n)\) . Здесь входное значение \(n\) обозначает число раундов деления, а возвращаемое значение count обозначает общее число делений.
def exponential(n: int) -> int:
"""Экспоненциальная сложность (итеративная реализация)"""
count = 0
base = 1
# На каждом шаге клетка делится надвое, образуя последовательность 1, 2, 4, 8, ..., 2^(n-1)
for _ in range(n):
for _ in range(base):
count += 1
base *= 2
# count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
return count
/* Экспоненциальная сложность (итеративная реализация) */
int exponential(int n) {
int count = 0, base = 1;
// На каждом шаге клетка делится надвое, образуя последовательность 1, 2, 4, 8, ..., 2^(n-1)
for (int i = 0; i < n; i++) {
for (int j = 0; j < base; j++) {
count++;
}
base *= 2;
}
// count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
return count;
}
/* Экспоненциальная сложность (итеративная реализация) */
int exponential(int n) {
int count = 0, base = 1;
// На каждом шаге клетка делится надвое, образуя последовательность 1, 2, 4, 8, ..., 2^(n-1)
for (int i = 0; i < n; i++) {
for (int j = 0; j < base; j++) {
count++;
}
base *= 2;
}
// count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
return count;
}
/* Экспоненциальная сложность (итеративная реализация) */
int Exponential(int n) {
int count = 0, bas = 1;
// На каждом шаге клетка делится надвое, образуя последовательность 1, 2, 4, 8, ..., 2^(n-1)
for (int i = 0; i < n; i++) {
for (int j = 0; j < bas; j++) {
count++;
}
bas *= 2;
}
// count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
return count;
}
/* Экспоненциальная сложность (итеративная реализация) */
func exponential(n int) int {
count, base := 0, 1
// На каждом шаге клетка делится надвое, образуя последовательность 1, 2, 4, 8, ..., 2^(n-1)
for i := 0; i < n; i++ {
for j := 0; j < base; j++ {
count++
}
base *= 2
}
// count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
return count
}
/* Экспоненциальная сложность (итеративная реализация) */
func exponential(n: Int) -> Int {
var count = 0
var base = 1
// На каждом шаге клетка делится надвое, образуя последовательность 1, 2, 4, 8, ..., 2^(n-1)
for _ in 0 ..< n {
for _ in 0 ..< base {
count += 1
}
base *= 2
}
// count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
return count
}
/* Экспоненциальная сложность (итеративная реализация) */
function exponential(n) {
let count = 0,
base = 1;
// На каждом шаге клетка делится надвое, образуя последовательность 1, 2, 4, 8, ..., 2^(n-1)
for (let i = 0; i < n; i++) {
for (let j = 0; j < base; j++) {
count++;
}
base *= 2;
}
// count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
return count;
}
/* Экспоненциальная сложность (итеративная реализация) */
function exponential(n: number): number {
let count = 0,
base = 1;
// На каждом шаге клетка делится надвое, образуя последовательность 1, 2, 4, 8, ..., 2^(n-1)
for (let i = 0; i < n; i++) {
for (let j = 0; j < base; j++) {
count++;
}
base *= 2;
}
// count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
return count;
}
/* Экспоненциальная сложность (итеративная реализация) */
int exponential(int n) {
int count = 0, base = 1;
// На каждом шаге клетка делится надвое, образуя последовательность 1, 2, 4, 8, ..., 2^(n-1)
for (var i = 0; i < n; i++) {
for (var j = 0; j < base; j++) {
count++;
}
base *= 2;
}
// count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
return count;
}
/* Экспоненциальная сложность (итеративная реализация) */
fn exponential(n: i32) -> i32 {
let mut count = 0;
let mut base = 1;
// На каждом шаге клетка делится надвое, образуя последовательность 1, 2, 4, 8, ..., 2^(n-1)
for _ in 0..n {
for _ in 0..base {
count += 1
}
base *= 2;
}
// count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
count
}
/* Экспоненциальная сложность (итеративная реализация) */
int exponential(int n) {
int count = 0;
int bas = 1;
// На каждом шаге клетка делится надвое, образуя последовательность 1, 2, 4, 8, ..., 2^(n-1)
for (int i = 0; i < n; i++) {
for (int j = 0; j < bas; j++) {
count++;
}
bas *= 2;
}
// count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
return count;
}
/* Экспоненциальная сложность (итеративная реализация) */
fun exponential(n: Int): Int {
var count = 0
var base = 1
// На каждом шаге клетка делится надвое, образуя последовательность 1, 2, 4, 8, ..., 2^(n-1)
for (i in 0..<n) {
for (j in 0..<base) {
count++
}
base *= 2
}
// count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
return count
}
### Квадратичная сложность ###
def quadratic(n)
count = 0
# Число итераций квадратично зависит от размера данных n
for i in 0...n
for j in 0...n
count += 1
end
end
count
end
# ## Квадратичная сложность (пузырьковая сортировка) ###
def bubble_sort(nums)
count = 0 # Счетчик
# Внешний цикл: неотсортированный диапазон [0, i]
for i in (nums.length - 1).downto(0)
# Внутренний цикл: переместить максимальный элемент неотсортированного диапазона [0, i] в его правый конец
for j in 0...i
if nums[j] > nums[j + 1]
# Поменять местами nums[j] и nums[j + 1]
tmp = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 # Обмен элементов включает 3 элементарные операции
end
end
end
count
end
# ## Экспоненциальная сложность (итеративная реализация) ###
def exponential(n)
count, base = 0, 1
# На каждом шаге клетка делится надвое, образуя последовательность 1, 2, 4, 8, ..., 2^(n-1)
(0...n).each do
(0...base).each { count += 1 }
base *= 2
end
# count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
count
end
Визуализация кода
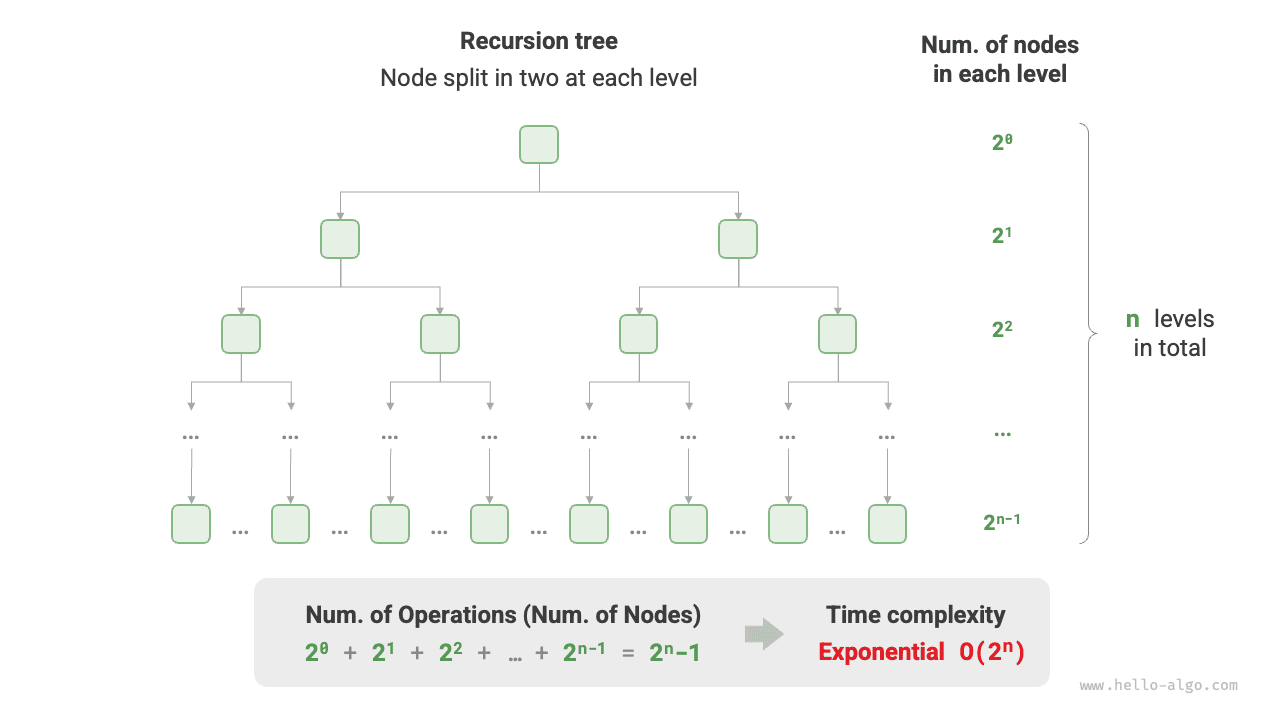
Рисунок 2-11 Экспоненциальная временная сложность
В реальных алгоритмах экспоненциальная сложность также часто встречается в рекурсивных функциях. Например, в следующем коде процесс рекурсивно делится надвое и останавливается после \(n\) разбиений:
### Квадратичная сложность ###
def quadratic(n)
count = 0
# Число итераций квадратично зависит от размера данных n
for i in 0...n
for j in 0...n
count += 1
end
end
count
end
# ## Квадратичная сложность (пузырьковая сортировка) ###
def bubble_sort(nums)
count = 0 # Счетчик
# Внешний цикл: неотсортированный диапазон [0, i]
for i in (nums.length - 1).downto(0)
# Внутренний цикл: переместить максимальный элемент неотсортированного диапазона [0, i] в его правый конец
for j in 0...i
if nums[j] > nums[j + 1]
# Поменять местами nums[j] и nums[j + 1]
tmp = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 # Обмен элементов включает 3 элементарные операции
end
end
end
count
end
# ## Экспоненциальная сложность (итеративная реализация) ###
def exponential(n)
count, base = 0, 1
# На каждом шаге клетка делится надвое, образуя последовательность 1, 2, 4, 8, ..., 2^(n-1)
(0...n).each do
(0...base).each { count += 1 }
base *= 2
end
# count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
count
end
# ## Экспоненциальная сложность (рекурсивная реализация) ###
def exp_recur(n)
return 1 if n == 1
exp_recur(n - 1) + exp_recur(n - 1) + 1
end
Визуализация кода
Экспоненциальный рост происходит очень быстро и часто встречается в переборных методах, грубой силе, поиске с возвратом и тому подобных подходах. Для задач большого масштаба экспоненциальная сложность неприемлема, и обычно приходится применять динамическое программирование, жадные алгоритмы и другие стратегии.
5. Логарифмическая сложность \(O(\log n)\)¶
В противоположность экспоненциальной, логарифмическая сложность описывает ситуацию, когда в каждом раунде размер задачи уменьшается вдвое. Пусть размер входных данных равен \(n\). Так как на каждом шаге размер уменьшается вдвое, число итераций равно \(\log_2 n\) , то есть является обратной функцией к \(2^n\) .
На рисунке 2-12 и в следующем коде моделируется процесс, в котором в каждом раунде размер задачи уменьшается вдвое. Временная сложность равна \(O(\log_2 n)\) и кратко записывается как \(O(\log n)\) :
### Квадратичная сложность ###
def quadratic(n)
count = 0
# Число итераций квадратично зависит от размера данных n
for i in 0...n
for j in 0...n
count += 1
end
end
count
end
# ## Квадратичная сложность (пузырьковая сортировка) ###
def bubble_sort(nums)
count = 0 # Счетчик
# Внешний цикл: неотсортированный диапазон [0, i]
for i in (nums.length - 1).downto(0)
# Внутренний цикл: переместить максимальный элемент неотсортированного диапазона [0, i] в его правый конец
for j in 0...i
if nums[j] > nums[j + 1]
# Поменять местами nums[j] и nums[j + 1]
tmp = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 # Обмен элементов включает 3 элементарные операции
end
end
end
count
end
# ## Экспоненциальная сложность (итеративная реализация) ###
def exponential(n)
count, base = 0, 1
# На каждом шаге клетка делится надвое, образуя последовательность 1, 2, 4, 8, ..., 2^(n-1)
(0...n).each do
(0...base).each { count += 1 }
base *= 2
end
# count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
count
end
# ## Экспоненциальная сложность (рекурсивная реализация) ###
def exp_recur(n)
return 1 if n == 1
exp_recur(n - 1) + exp_recur(n - 1) + 1
end
# ## Логарифмическая сложность (итеративная реализация) ###
def logarithmic(n)
count = 0
while n > 1
n /= 2
count += 1
end
count
end
Визуализация кода
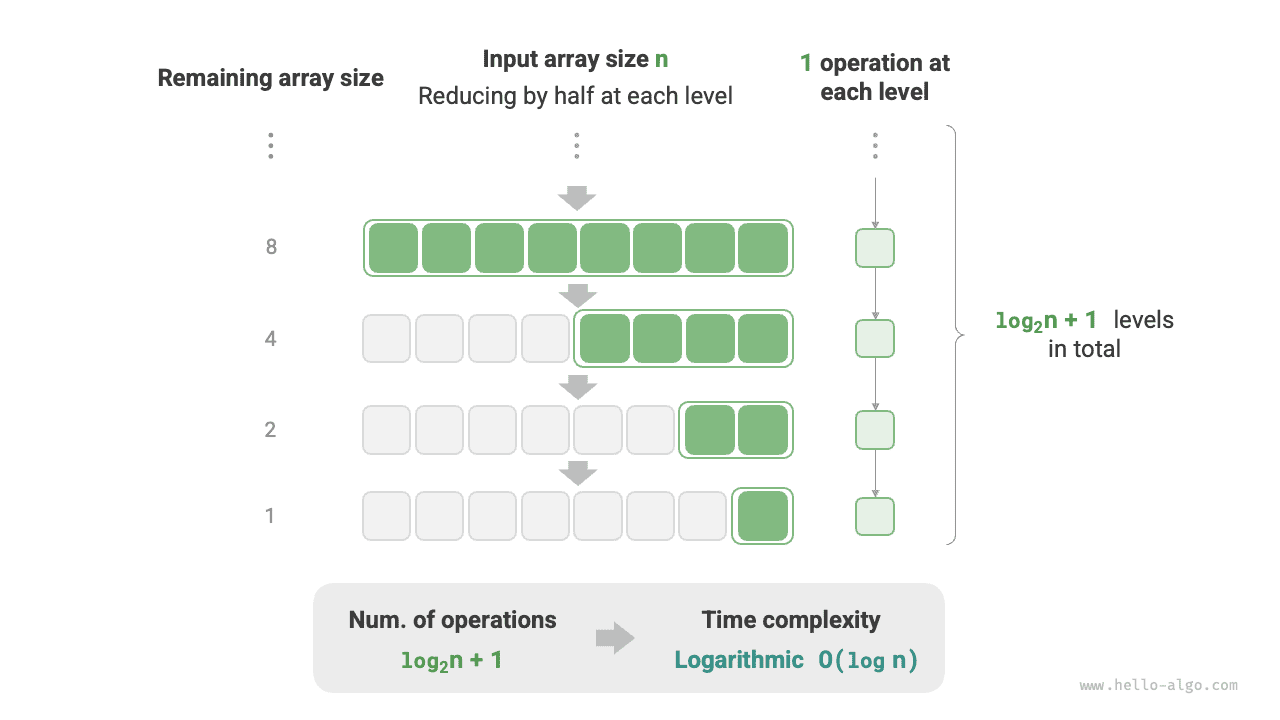
Рисунок 2-12 Логарифмическая временная сложность
Подобно экспоненциальной сложности, логарифмическая также часто встречается в рекурсивных функциях. Следующий код формирует рекурсивное дерево высотой \(\log_2 n\) :
### Квадратичная сложность ###
def quadratic(n)
count = 0
# Число итераций квадратично зависит от размера данных n
for i in 0...n
for j in 0...n
count += 1
end
end
count
end
# ## Квадратичная сложность (пузырьковая сортировка) ###
def bubble_sort(nums)
count = 0 # Счетчик
# Внешний цикл: неотсортированный диапазон [0, i]
for i in (nums.length - 1).downto(0)
# Внутренний цикл: переместить максимальный элемент неотсортированного диапазона [0, i] в его правый конец
for j in 0...i
if nums[j] > nums[j + 1]
# Поменять местами nums[j] и nums[j + 1]
tmp = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 # Обмен элементов включает 3 элементарные операции
end
end
end
count
end
# ## Экспоненциальная сложность (итеративная реализация) ###
def exponential(n)
count, base = 0, 1
# На каждом шаге клетка делится надвое, образуя последовательность 1, 2, 4, 8, ..., 2^(n-1)
(0...n).each do
(0...base).each { count += 1 }
base *= 2
end
# count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
count
end
# ## Экспоненциальная сложность (рекурсивная реализация) ###
def exp_recur(n)
return 1 if n == 1
exp_recur(n - 1) + exp_recur(n - 1) + 1
end
# ## Логарифмическая сложность (итеративная реализация) ###
def logarithmic(n)
count = 0
while n > 1
n /= 2
count += 1
end
count
end
# ## Логарифмическая сложность (рекурсивная реализация) ###
def log_recur(n)
return 0 unless n > 1
log_recur(n / 2) + 1
end
Визуализация кода
Логарифмическая сложность часто встречается в алгоритмах, основанных на стратегии «разделяй и властвуй», и отражает идеи разбиения на части и упрощения сложной задачи. Она растет медленно и считается одной из самых желательных временных сложностей после константной.
Каково основание у \(O(\log n)\) ?
Точнее говоря, «разделение на \(m\) частей» соответствует временной сложности \(O(\log_m n)\) . А по формуле перехода к другому основанию логарифма мы получаем равные по сложности выражения с разными основаниями:
Иными словами, основание \(m\) можно менять без влияния на сложность. Поэтому мы обычно опускаем основание \(m\) и напрямую записываем логарифмическую сложность как \(O(\log n)\) .
6. Линейно-логарифмическая сложность \(O(n \log n)\)¶
Линейно-логарифмическая сложность часто встречается в рекурсивных разбиениях, где временная сложность одного измерения равна \(O(\log n)\) , а другого - \(O(n)\) . Соответствующий код выглядит следующим образом:
def linear_log_recur(n: int) -> int:
"""Линейно-логарифмическая сложность"""
if n <= 1:
return 1
# Разделение надвое: размер подзадачи уменьшается вдвое
count = linear_log_recur(n // 2) + linear_log_recur(n // 2)
# Текущая подзадача содержит n операций
for _ in range(n):
count += 1
return count
Визуализация кода
На рисунке 2-13 показано, как возникает линейно-логарифмическая сложность. Общее число операций на каждом уровне бинарного дерева равно \(n\) , а дерево имеет \(\log_2 n + 1\) уровней, поэтому временная сложность равна \(O(n \log n)\) .
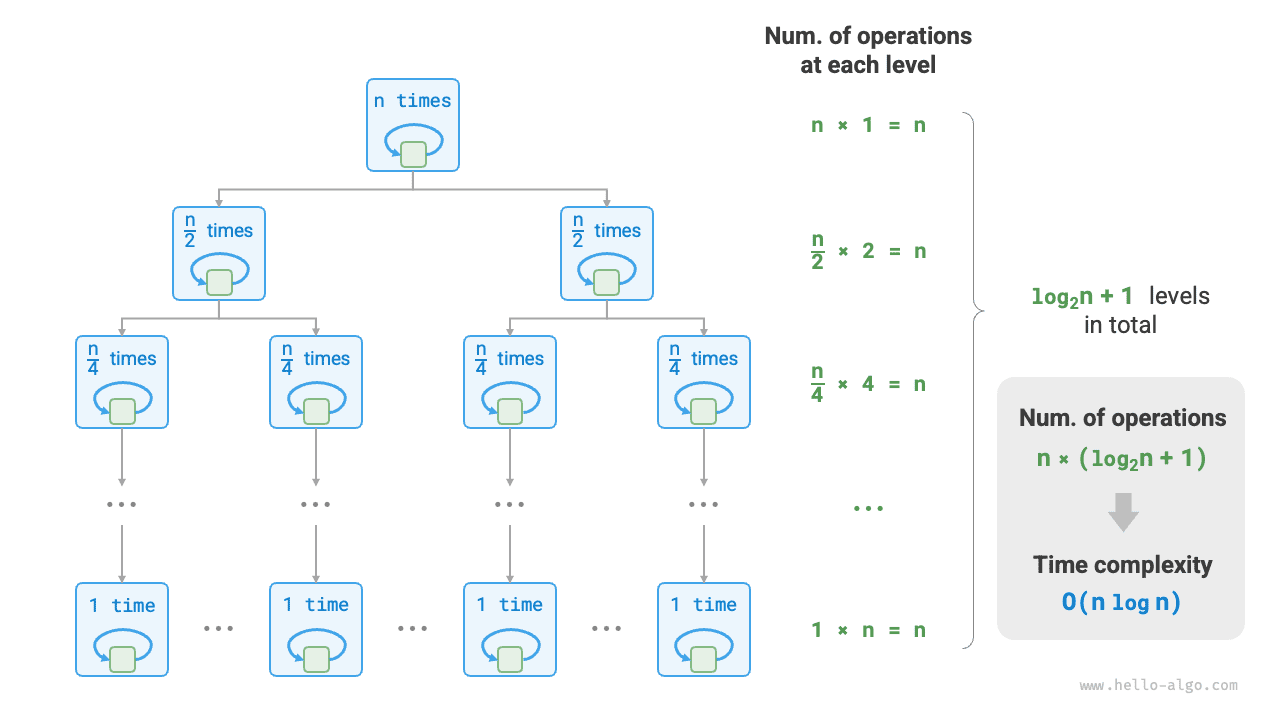
Рисунок 2-13 Линейно-логарифмическая временная сложность
Временная сложность основных алгоритмов сортировки обычно равна \(O(n \log n)\) , например у быстрой сортировки, сортировки слиянием, пирамидальной сортировки и т.д.
7. Факториальная сложность \(O(n!)\)¶
Факториальная сложность соответствует математической задаче полной перестановки. Если даны \(n\) попарно различных элементов, то число всех возможных перестановок равно:
Факториал обычно реализуют через рекурсию. Как показано на рисунке 2-14 и в следующем коде, на первом уровне происходит ветвление на \(n\) подзадач, на втором - на \(n - 1\) и так далее, пока на \(n\)-м уровне ветвление не прекращается:
### Линейно-логарифмическая сложность ###
def linear_log_recur(n)
return 1 unless n > 1
count = linear_log_recur(n / 2) + linear_log_recur(n / 2)
(0...n).each { count += 1 }
count
end
# ## Факториальная сложность (рекурсивная реализация) ###
def factorial_recur(n)
return 1 if n == 0
count = 0
# Из одного получается n
(0...n).each { count += factorial_recur(n - 1) }
count
end
Визуализация кода
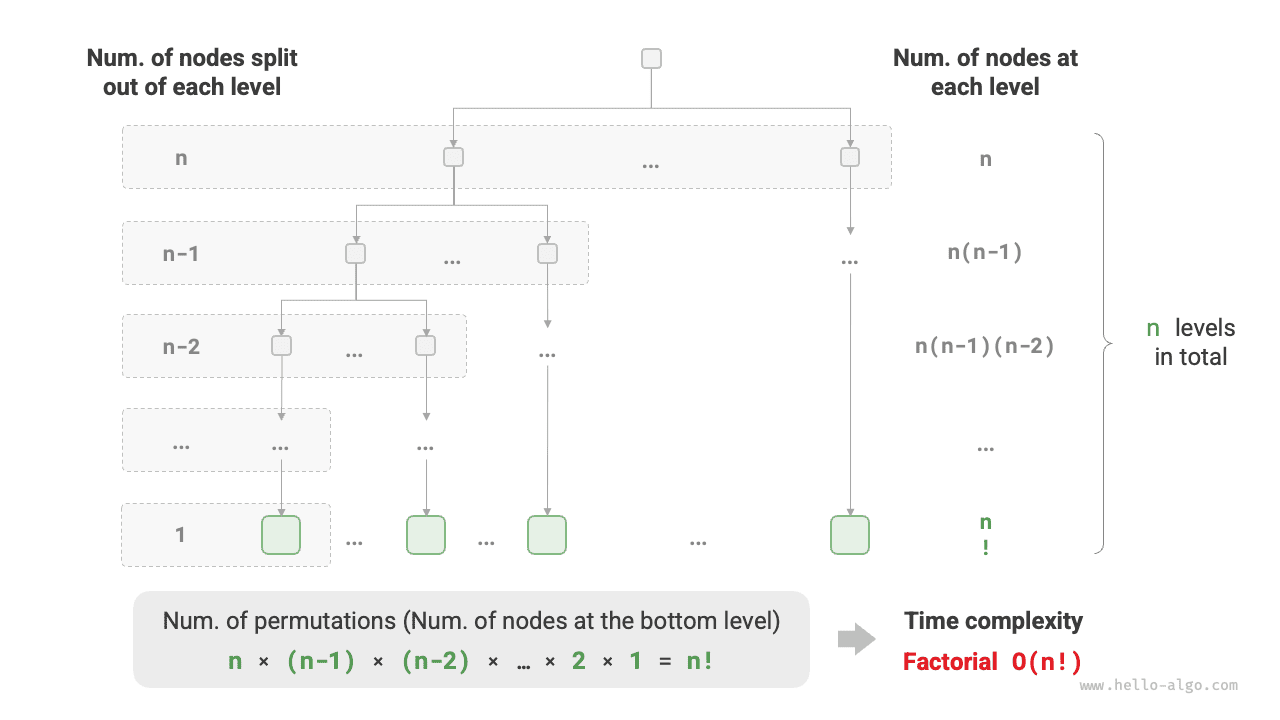
Рисунок 2-14 Факториальная временная сложность
Следует отметить, что поскольку при \(n \geq 4\) всегда выполняется \(n! > 2^n\) , факториальная сложность растет еще быстрее, чем экспоненциальная, и при больших \(n\) становится неприемлемой.
2.3.5 Худшая, лучшая и средняя временная сложность¶
Временная эффективность алгоритма часто не фиксирована, а зависит от распределения входных данных. Предположим, на вход подается массив nums длины \(n\) , состоящий из чисел от \(1\) до \(n\) , каждое из которых встречается ровно один раз. При этом порядок элементов случайно перемешан. Задача состоит в том, чтобы вернуть индекс элемента \(1\) . Тогда можно сделать следующие выводы.
- Когда
nums = [?, ?, ..., 1], то есть когда последний элемент равен \(1\) , нужно полностью пройти по массиву, что дает худшую временную сложность \(O(n)\) . - Когда
nums = [1, ?, ?, ...], то есть когда первый элемент равен \(1\) , независимо от длины массива продолжать обход не нужно, что дает лучшую временную сложность \(\Omega(1)\) .
Худшая временная сложность соответствует асимптотической верхней границе функции и обозначается нотацией Big \(O\) . Соответственно, лучшая временная сложность соответствует асимптотической нижней границе функции и обозначается символом \(\Omega\) :
def random_numbers(n: int) -> list[int]:
"""Сгенерировать массив с элементами 1, 2, ..., n в случайном порядке"""
# Создать массив nums =: 1, 2, 3, ..., n
nums = [i for i in range(1, n + 1)]
# Случайно перемешать элементы массива
random.shuffle(nums)
return nums
def find_one(nums: list[int]) -> int:
"""Найти индекс числа 1 в массиве nums"""
for i in range(len(nums)):
# Когда элемент 1 находится в начале массива, достигается лучшая временная сложность O(1)
# Когда элемент 1 находится в конце массива, достигается худшая временная сложность O(n)
if nums[i] == 1:
return i
return -1
/* Создать массив с элементами { 1, 2, ..., n } в случайном порядке */
vector<int> randomNumbers(int n) {
vector<int> nums(n);
// Создать массив nums = { 1, 2, 3, ..., n }
for (int i = 0; i < n; i++) {
nums[i] = i + 1;
}
// Использовать системное время для генерации случайного seed
unsigned seed = chrono::system_clock::now().time_since_epoch().count();
// Случайно перемешать элементы массива
shuffle(nums.begin(), nums.end(), default_random_engine(seed));
return nums;
}
/* Найти индекс числа 1 в массиве nums */
int findOne(vector<int> &nums) {
for (int i = 0; i < nums.size(); i++) {
// Когда элемент 1 находится в начале массива, достигается лучшая временная сложность O(1)
// Когда элемент 1 находится в конце массива, достигается худшая временная сложность O(n)
if (nums[i] == 1)
return i;
}
return -1;
}
/* Создать массив с элементами { 1, 2, ..., n } в случайном порядке */
int[] randomNumbers(int n) {
Integer[] nums = new Integer[n];
// Создать массив nums = { 1, 2, 3, ..., n }
for (int i = 0; i < n; i++) {
nums[i] = i + 1;
}
// Случайно перемешать элементы массива
Collections.shuffle(Arrays.asList(nums));
// Integer[] -> int[]
int[] res = new int[n];
for (int i = 0; i < n; i++) {
res[i] = nums[i];
}
return res;
}
/* Найти индекс числа 1 в массиве nums */
int findOne(int[] nums) {
for (int i = 0; i < nums.length; i++) {
// Когда элемент 1 находится в начале массива, достигается лучшая временная сложность O(1)
// Когда элемент 1 находится в конце массива, достигается худшая временная сложность O(n)
if (nums[i] == 1)
return i;
}
return -1;
}
/* Создать массив с элементами { 1, 2, ..., n } в случайном порядке */
int[] RandomNumbers(int n) {
int[] nums = new int[n];
// Создать массив nums = { 1, 2, 3, ..., n }
for (int i = 0; i < n; i++) {
nums[i] = i + 1;
}
// Случайно перемешать элементы массива
for (int i = 0; i < nums.Length; i++) {
int index = new Random().Next(i, nums.Length);
(nums[i], nums[index]) = (nums[index], nums[i]);
}
return nums;
}
/* Найти индекс числа 1 в массиве nums */
int FindOne(int[] nums) {
for (int i = 0; i < nums.Length; i++) {
// Когда элемент 1 находится в начале массива, достигается лучшая временная сложность O(1)
// Когда элемент 1 находится в конце массива, достигается худшая временная сложность O(n)
if (nums[i] == 1)
return i;
}
return -1;
}
/* Создать массив с элементами { 1, 2, ..., n } в случайном порядке */
func randomNumbers(n int) []int {
nums := make([]int, n)
// Создать массив nums = { 1, 2, 3, ..., n }
for i := 0; i < n; i++ {
nums[i] = i + 1
}
// Случайно перемешать элементы массива
rand.Shuffle(len(nums), func(i, j int) {
nums[i], nums[j] = nums[j], nums[i]
})
return nums
}
/* Найти индекс числа 1 в массиве nums */
func findOne(nums []int) int {
for i := 0; i < len(nums); i++ {
// Когда элемент 1 находится в начале массива, достигается лучшая временная сложность O(1)
// Когда элемент 1 находится в конце массива, достигается худшая временная сложность O(n)
if nums[i] == 1 {
return i
}
}
return -1
}
/* Создать массив с элементами { 1, 2, ..., n } в случайном порядке */
func randomNumbers(n: Int) -> [Int] {
// Создать массив nums = { 1, 2, 3, ..., n }
var nums = Array(1 ... n)
// Случайно перемешать элементы массива
nums.shuffle()
return nums
}
/* Найти индекс числа 1 в массиве nums */
func findOne(nums: [Int]) -> Int {
for i in nums.indices {
// Когда элемент 1 находится в начале массива, достигается лучшая временная сложность O(1)
// Когда элемент 1 находится в конце массива, достигается худшая временная сложность O(n)
if nums[i] == 1 {
return i
}
}
return -1
}
/* Создать массив с элементами { 1, 2, ..., n } в случайном порядке */
function randomNumbers(n) {
const nums = Array(n);
// Создать массив nums = { 1, 2, 3, ..., n }
for (let i = 0; i < n; i++) {
nums[i] = i + 1;
}
// Случайно перемешать элементы массива
for (let i = 0; i < n; i++) {
const r = Math.floor(Math.random() * (i + 1));
const temp = nums[i];
nums[i] = nums[r];
nums[r] = temp;
}
return nums;
}
/* Найти индекс числа 1 в массиве nums */
function findOne(nums) {
for (let i = 0; i < nums.length; i++) {
// Когда элемент 1 находится в начале массива, достигается лучшая временная сложность O(1)
// Когда элемент 1 находится в конце массива, достигается худшая временная сложность O(n)
if (nums[i] === 1) {
return i;
}
}
return -1;
}
/* Создать массив с элементами { 1, 2, ..., n } в случайном порядке */
function randomNumbers(n: number): number[] {
const nums = Array(n);
// Создать массив nums = { 1, 2, 3, ..., n }
for (let i = 0; i < n; i++) {
nums[i] = i + 1;
}
// Случайно перемешать элементы массива
for (let i = 0; i < n; i++) {
const r = Math.floor(Math.random() * (i + 1));
const temp = nums[i];
nums[i] = nums[r];
nums[r] = temp;
}
return nums;
}
/* Найти индекс числа 1 в массиве nums */
function findOne(nums: number[]): number {
for (let i = 0; i < nums.length; i++) {
// Когда элемент 1 находится в начале массива, достигается лучшая временная сложность O(1)
// Когда элемент 1 находится в конце массива, достигается худшая временная сложность O(n)
if (nums[i] === 1) {
return i;
}
}
return -1;
}
/* Создать массив с элементами { 1, 2, ..., n } в случайном порядке */
List<int> randomNumbers(int n) {
final nums = List.filled(n, 0);
// Создать массив nums = { 1, 2, 3, ..., n }
for (var i = 0; i < n; i++) {
nums[i] = i + 1;
}
// Случайно перемешать элементы массива
nums.shuffle();
return nums;
}
/* Найти индекс числа 1 в массиве nums */
int findOne(List<int> nums) {
for (var i = 0; i < nums.length; i++) {
// Когда элемент 1 находится в начале массива, достигается лучшая временная сложность O(1)
// Когда элемент 1 находится в конце массива, достигается худшая временная сложность O(n)
if (nums[i] == 1) return i;
}
return -1;
}
/* Создать массив с элементами { 1, 2, ..., n } в случайном порядке */
fn random_numbers(n: i32) -> Vec<i32> {
// Создать массив nums = { 1, 2, 3, ..., n }
let mut nums = (1..=n).collect::<Vec<i32>>();
// Случайно перемешать элементы массива
nums.shuffle(&mut thread_rng());
nums
}
/* Найти индекс числа 1 в массиве nums */
fn find_one(nums: &[i32]) -> Option<usize> {
for i in 0..nums.len() {
// Когда элемент 1 находится в начале массива, достигается лучшая временная сложность O(1)
// Когда элемент 1 находится в конце массива, достигается худшая временная сложность O(n)
if nums[i] == 1 {
return Some(i);
}
}
None
}
/* Создать массив с элементами { 1, 2, ..., n } в случайном порядке */
int *randomNumbers(int n) {
// Выделить память в куче (создать одномерный массив переменной длины: число элементов равно n, тип элементов — int)
int *nums = (int *)malloc(n * sizeof(int));
// Создать массив nums = { 1, 2, 3, ..., n }
for (int i = 0; i < n; i++) {
nums[i] = i + 1;
}
// Случайно перемешать элементы массива
for (int i = n - 1; i > 0; i--) {
int j = rand() % (i + 1);
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
return nums;
}
/* Найти индекс числа 1 в массиве nums */
int findOne(int *nums, int n) {
for (int i = 0; i < n; i++) {
// Когда элемент 1 находится в начале массива, достигается лучшая временная сложность O(1)
// Когда элемент 1 находится в конце массива, достигается худшая временная сложность O(n)
if (nums[i] == 1)
return i;
}
return -1;
}
/* Создать массив с элементами { 1, 2, ..., n } в случайном порядке */
fun randomNumbers(n: Int): Array<Int?> {
val nums = IntArray(n)
// Создать массив nums = { 1, 2, 3, ..., n }
for (i in 0..<n) {
nums[i] = i + 1
}
// Случайно перемешать элементы массива
nums.shuffle()
val res = arrayOfNulls<Int>(n)
for (i in 0..<n) {
res[i] = nums[i]
}
return res
}
/* Найти индекс числа 1 в массиве nums */
fun findOne(nums: Array<Int?>): Int {
for (i in nums.indices) {
// Когда элемент 1 находится в начале массива, достигается лучшая временная сложность O(1)
// Когда элемент 1 находится в конце массива, достигается худшая временная сложность O(n)
if (nums[i] == 1)
return i
}
return -1
}
### Создать массив с элементами: 1, 2, ..., n в случайном порядке ###
def random_numbers(n)
# Создать массив nums =: 1, 2, 3, ..., n
nums = Array.new(n) { |i| i + 1 }
# Случайно перемешать элементы массива
nums.shuffle!
end
### Найти индекс числа 1 в массиве nums ###
def find_one(nums)
for i in 0...nums.length
# Когда элемент 1 находится в начале массива, достигается лучшая временная сложность O(1)
# Когда элемент 1 находится в конце массива, достигается худшая временная сложность O(n)
return i if nums[i] == 1
end
-1
end
Визуализация кода
Стоит отметить, что на практике лучшая временная сложность используется редко, поскольку обычно она достигается лишь с очень малой вероятностью и может вводить в заблуждение. Худшая временная сложность гораздо практичнее, потому что задает безопасную оценку эффективности и позволяет уверенно использовать алгоритм.
Из приведенного выше примера видно, что худшая и лучшая временные сложности возникают только при особых распределениях данных. Вероятность таких случаев может быть низкой, и они не всегда реально отражают эффективность алгоритма. Напротив, средняя временная сложность способна показать эффективность алгоритма на случайных входных данных и обозначается символом \(\Theta\) .
Для некоторых алгоритмов можно относительно просто вывести средний случай при случайном распределении данных. Например, в приведенном выше примере входной массив перемешан, а вероятность появления элемента \(1\) на любом индексе одинакова. Следовательно, среднее число итераций алгоритма равно половине длины массива, то есть \(n / 2\) , а средняя временная сложность равна \(\Theta(n / 2) = \Theta(n)\) .
Однако для более сложных алгоритмов вычислить среднюю временную сложность часто непросто, потому что трудно проанализировать полное математическое ожидание на заданном распределении данных. В таких случаях обычно используют худшую временную сложность как критерий оценки эффективности алгоритма.
Почему символ \(\Theta\) встречается так редко?
Возможно, потому что символ \(O\) звучит слишком привычно, и мы часто используем его для обозначения средней временной сложности. Но строго говоря, это некорректно. В этой книге и в других материалах, если встретится выражение вроде «средняя временная сложность \(O(n)\)», просто понимай его как \(\Theta(n)\) .