3.4 Кодирование символов *¶
В компьютере все данные хранятся в виде двоичных чисел, и символьный тип данных char не является исключением. Для представления символов необходимо задать «таблицу символов», которая устанавливает взаимно-однозначное соответствие между каждым символом и двоичным числом. С помощью этой таблицы компьютер может преобразовывать двоичные числа в символы.
3.4.1 Таблица символов ASCII¶
Код ASCII - это самая ранняя таблица символов. Ее полное название - American Standard Code for Information Interchange (американский стандартный код обмена информацией). Для представления символов в ней используются 7 двоичных битов (нижние 7 битов одного байта), что позволяет закодировать до 128 различных символов. Как показано на рисунке 3-6, ASCII включает заглавные и строчные буквы английского алфавита, цифры 0 ~ 9, некоторые знаки препинания, а также некоторые управляющие символы (например перевод строки и табуляцию).
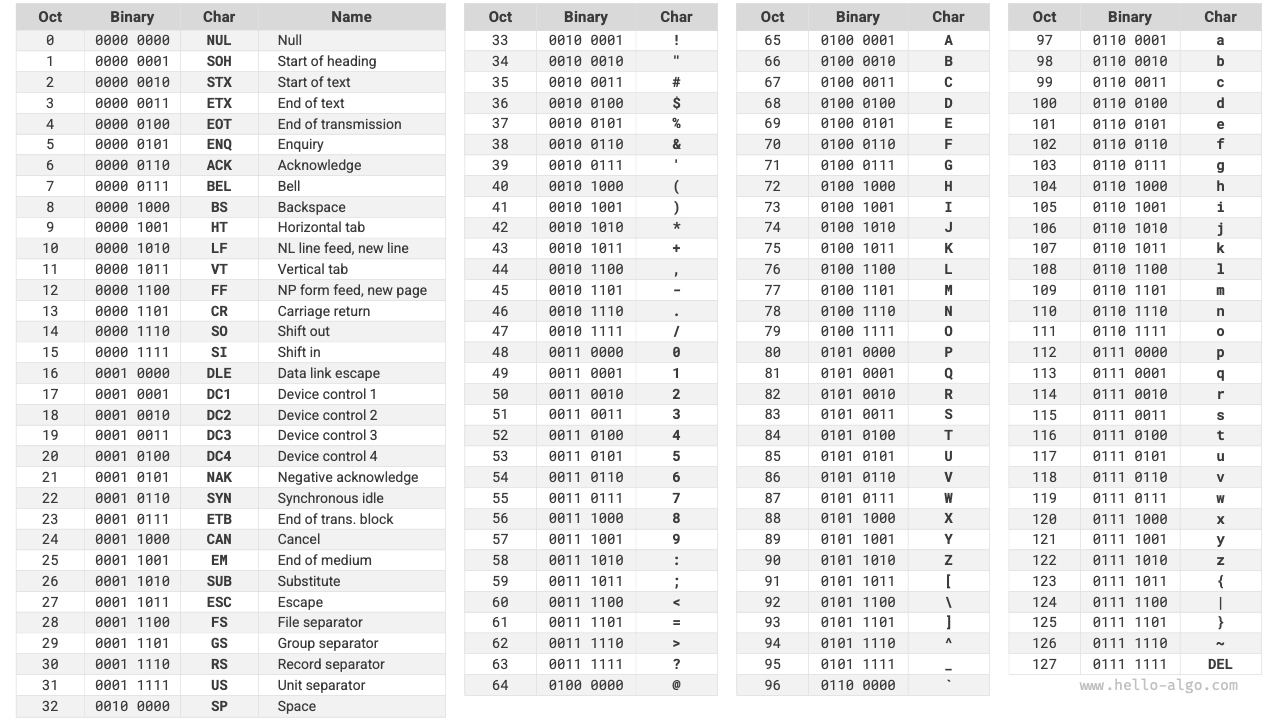
Рисунок 3-6 Таблица ASCII
Однако код ASCII может представлять только английский язык. С развитием компьютерных технологий появилась таблица символов EASCII, способная охватывать больше языков. Она расширяет 7-битную основу ASCII до 8 битов и может представлять 256 различных символов.
Во всем мире постепенно появились разные таблицы EASCII, подходящие для разных регионов. Первые 128 символов в этих таблицах одинаковы и соответствуют ASCII, а последние 128 символов определяются по-разному, чтобы удовлетворять потребностям разных языков.
3.4.2 Таблица символов GBK¶
Позже люди обнаружили, что кодов EASCII все равно недостаточно для количества символов во многих языках. Например, китайских иероглифов существует почти сто тысяч, а в повседневном употреблении нужны тысячи. В 1980 году Государственное управление стандартов Китая выпустило таблицу символов GB2312, включающую 6763 иероглифа, что в основном удовлетворило потребности компьютерной обработки китайского текста.
Однако GB2312 не умеет работать с некоторыми редкими иероглифами и традиционными формами письма. Таблица символов GBK представляет собой расширение GB2312 и в общей сложности содержит 21886 иероглифов. В схеме кодирования GBK символы ASCII представляются одним байтом, а китайские иероглифы - двумя байтами.
3.4.3 Таблица символов Unicode¶
С бурным развитием компьютерной техники таблицы символов и стандарты кодирования начали стремительно множиться, и это породило множество проблем. С одной стороны, такие таблицы обычно определяли символы только для конкретных языков и не могли нормально работать в многоязычной среде. С другой стороны, для одного и того же языка существовало несколько стандартов кодирования. Если две машины использовали разные стандарты, при обмене информацией возникали искажения текста.
Исследователи той эпохи задумались: если создать достаточно полную таблицу символов, которая включит все языки и знаки мира, разве это не решит проблемы многоязычной среды и искаженного текста? Под влиянием этой идеи и появилась большая и всеобъемлющая таблица символов Unicode.
Unicode по-китайски называется «единый код» и теоретически способен вместить более миллиона символов. Его цель - собрать символы со всего мира в единую таблицу символов, предоставить универсальный стандарт для обработки и отображения текстов на разных языках и уменьшить количество проблем с искажением текста, вызванных различиями стандартов кодирования. С момента публикации в 1991 году Unicode непрерывно расширялся, добавляя новые языки и символы. По состоянию на сентябрь 2022 года Unicode уже включал 149186 символов, в том числе буквы разных языков, знаки, а также эмодзи.
Как универсальный набор символов, Unicode по сути присваивает каждому символу уникальную «кодовую точку» (числовой идентификатор символа), диапазон которой составляет от U+0000 до U+10FFFF, образуя единое пространство нумерации символов. Однако Unicode не определяет, как именно хранить эти кодовые точки в компьютере. Тут неизбежно возникает вопрос: если в одном тексте одновременно встречаются кодовые точки Unicode разной длины, как система должна разбирать символы? Например, если дан код длиной 2 байта, как понять, является ли это одним 2-байтовым символом или двумя 1-байтовыми?
Для этой проблемы прямолинейное решение состоит в том, чтобы хранить все символы в кодировке одинаковой длины. Как показано на рисунке 3-7, каждый символ в «Hello» занимает 1 байт, а каждый символ в «алгоритм» занимает 2 байта. Мы можем дополнить старшие биты нулями и закодировать все символы в «Hello алгоритм» в виде 2-байтовых единиц. Тогда система сможет считывать по одному символу каждые 2 байта и восстановить эту фразу.

Рисунок 3-7 Пример кодирования Unicode
Однако ASCII уже показал нам, что для кодирования английского текста достаточно 1 байта. Если использовать описанную выше схему, английский текст будет занимать вдвое больше памяти, чем при ASCII, а это очень неэффективно. Поэтому нам нужен более эффективный способ кодирования Unicode.
3.4.4 Кодировка UTF-8¶
Сегодня UTF-8 стала самым широко используемым способом кодирования Unicode в мире. Это кодировка переменной длины, использующая от 1 до 4 байт на символ в зависимости от его сложности. Символам ASCII нужен только 1 байт, латинским и греческим буквам - 2 байта, часто используемым китайским символам - 3 байта, а некоторым редким символам - 4 байта.
Правила кодирования UTF-8 не слишком сложны и делятся на два случая.
- Для символов длиной 1 байт старший бит устанавливается в \(0\) , а оставшиеся 7 битов содержат кодовую точку Unicode. Стоит отметить, что символы ASCII занимают первые 128 кодовых точек в наборе Unicode. Иными словами, кодировка UTF-8 обратно совместима с ASCII. Это означает, что мы можем использовать UTF-8 для разбора очень старых ASCII-текстов.
- Для символов длиной \(n\) байт (где \(n > 1\)) старшие \(n\) битов первого байта устанавливаются в \(1\) , а \((n + 1)\)-й бит устанавливается в \(0\). Начиная со второго байта, старшие 2 бита каждого байта устанавливаются в \(10\). Все остальные биты используются для заполнения кодовой точки Unicode соответствующего символа.
На рисунке 3-8 показана UTF-8-кодировка для строки «Hello алгоритм». Можно заметить, что поскольку старшие \(n\) битов установлены в \(1\) , система может определить длину символа как \(n\) , подсчитав число ведущих единиц.
Но почему старшие 2 бита всех остальных байтов устанавливаются в \(10\) ? На самом деле это \(10\) играет роль контрольного маркера. Если система начнет разбирать текст с неверного байта, префикс \(10\) поможет быстро обнаружить аномалию.
Причина выбора \(10\) в качестве контрольного маркера в том, что по правилам UTF-8 символ не может иметь старшие два бита, равные \(10\) . Это можно доказать от противного: если предположить, что у некоторого символа старшие два бита равны \(10\) , то длина такого символа должна быть 1 байт, то есть это ASCII. Но у ASCII старший бит обязан быть \(0\) , что противоречит предположению.

Рисунок 3-8 Пример кодировки UTF-8
Помимо UTF-8, распространены еще два следующих способа кодирования.
- Кодировка UTF-16: использует 2 или 4 байта для представления символа. Все символы ASCII и часто используемые неанглийские символы представляются 2 байтами. Небольшая часть символов требует 4 байта. Для 2-байтовых символов кодировка UTF-16 совпадает с кодовой точкой Unicode.
- Кодировка UTF-32: каждый символ занимает 4 байта. Это означает, что UTF-32 требует больше места, чем UTF-8 и UTF-16, особенно в текстах с большой долей ASCII-символов.
С точки зрения занимаемого места UTF-8 очень эффективна для английских символов, потому что им нужен всего 1 байт. А для некоторых неанглийских символов (например китайских) UTF-16 может быть эффективнее, потому что ей требуется только 2 байта, тогда как UTF-8 может потребовать 3 байта.
С точки зрения совместимости у UTF-8 наилучшая универсальность, и многие инструменты и библиотеки в первую очередь поддерживают именно UTF-8.
3.4.5 Кодирование символов в языках программирования¶
Для большинства языков программирования прошлого строки во время выполнения программы использовали фиксированные по длине кодировки, такие как UTF-16 или UTF-32. При кодировке фиксированной длины строку можно обрабатывать как массив, и такой подход дает следующие преимущества.
- Произвольный доступ: к строкам в UTF-16 легко осуществлять произвольный доступ. UTF-8 же является кодировкой переменной длины, поэтому, чтобы найти \(i\) -й символ, нужно пройти от начала строки до этого символа, а это требует \(O(n)\) времени.
- Подсчет длины строки: аналогично произвольному доступу, вычисление длины строки в UTF-16 - это операция \(O(1)\) . А вот вычисление длины строки в UTF-8 требует обхода всей строки.
- Строковые операции: многие операции со строками (разделение, конкатенация, вставка, удаление и т.д.) над строками в UTF-16 реализуются проще. При работе с UTF-8 обычно требуются дополнительные вычисления, чтобы не породить некорректную UTF-8-последовательность.
Вообще говоря, проектирование схем кодирования символов в языках программирования - очень интересная тема, в которой учитывается множество факторов.
- Тип
Stringв Java использует кодировку UTF-16, и каждый символ занимает 2 байта. Это связано с тем, что на раннем этапе проектирования Java считалось, что 16 битов достаточно для представления всех возможных символов. Но это оказалось неверным предположением. Позднее Unicode вышел за пределы 16 битов, поэтому символы в Java теперь могут представляться парой 16-битных значений (так называемой «суррогатной парой»). - Строки в JavaScript и TypeScript используют UTF-16 по причинам, похожим на Java. Когда Netscape впервые выпустила JavaScript в 1995 году, Unicode еще находился на ранней стадии развития, и 16-битного кодирования тогда было достаточно для представления всех символов Unicode.
- C# использует UTF-16 главным образом потому, что платформа .NET была разработана Microsoft, а многие технологии Microsoft (включая Windows) широко используют именно UTF-16.
Из-за недооценки общего числа символов перечисленным выше языкам пришлось использовать «суррогатные пары» для представления Unicode-символов длиной больше 16 бит. Это вынужденный компромисс. С одной стороны, в строках с суррогатными парами один символ может занимать 2 байта или 4 байта, из-за чего теряется преимущество кодировки фиксированной длины. С другой стороны, обработка суррогатных пар требует дополнительного кода, что повышает сложность разработки и отладки.
По этим причинам некоторые языки программирования предложили иные схемы кодирования.
strв Python использует Unicode и гибкое строковое представление, где длина хранимого символа зависит от наибольшей кодовой точки Unicode в строке. Если все символы строки принадлежат ASCII, каждый символ занимает 1 байт. Если есть символы за пределами ASCII, но все они лежат в базовой многоязычной плоскости (BMP), каждый символ занимает 2 байта. Если встречаются символы за пределами BMP, каждый символ занимает 4 байта.- Тип
stringв Go внутри использует кодировку UTF-8. Язык Go также предоставляет типrune, предназначенный для представления одной кодовой точки Unicode. - Типы
strиStringв Rust внутри используют UTF-8. В Rust также есть типchar, представляющий одну кодовую точку Unicode.
Следует помнить, что выше обсуждался способ хранения строк внутри языков программирования, а это не то же самое, что хранение строк в файлах или передача их по сети. При файловом хранении и сетевой передаче мы обычно кодируем строки в формате UTF-8, чтобы получить наилучшую совместимость и эффективность по занимаемому месту.